
Did you know that switching to Graviton4 can boost your Llama 3.1 inference throughput by over 160% compared to traditional x86 instances? If your machine learning bills are climbing, transitioning to AWS-native silicon is the most effective way to secure a 40% better price-performance ratio for your models.
Why Graviton is the new standard for ML inference
For years, the industry assumed that high-performance machine learning required power-hungry GPUs or expensive x86 processors. AWS Graviton has fundamentally shifted this math, particularly for inference workloads. Recent benchmarks indicate that Graviton3 delivers up to 1.8x faster deep learning inference than x86 by utilizing Neoverse V1 BF16 instructions. This isn’t just about raw speed; it is about reducing the cost of every individual prediction your model generates.
When you run AWS Graviton instance types like the C7g family, you benefit from an architecture where one vCPU maps directly to one physical core. Unlike x86 instances that rely on hyperthreading, Graviton provides consistent, predictable performance for the compute-intensive nature of machine learning. For natural language processing (NLP) models, using the ONNX Runtime on Graviton3 can yield up to a 65% speedup in FP32 inference, making it a powerhouse for tasks like sentiment analysis, translation, and real-time text summarization.
Benchmarking ML training on Graviton4
While inference is the most common use case for Graviton, the release of Graviton4 has expanded the possibilities for training, specifically for classical machine learning workloads. In side-by-side performance benchmarking for AWS Graviton, Graviton4 showed 53% faster XGBoost training than AMD and 34% faster than Intel. This allows data science teams to iterate faster without waiting for expensive GPU availability.
For many businesses, training smaller, specialized models on high-performance CPUs is significantly more cost-effective than provisioning large GPU clusters. The architectural advantages of Graviton4, including DDR5-5600 memory and improved Matrix Multiplication (MMLA) instructions, allow for higher memory bandwidth. This is critical because memory access is often the primary bottleneck in large-scale data processing. If your training jobs are CPU-bound, staying on x86 could be costing you twice as much as necessary, a gap clearly visible in our cost comparison between Graviton and Intel instances.
Optimized frameworks and SageMaker integration
You do not have to rebuild your entire machine learning stack from scratch to take advantage of these savings. AWS has heavily optimized common frameworks specifically for the ARM64 architecture, ensuring that your existing code can run efficiently.
- PyTorch 2.0 delivers up to 3.5x faster ResNet50 inference and 1.4x faster BERT inference compared to previous releases on Graviton.
- TensorFlow and Scikit-learn are natively supported in SageMaker’s Graviton-compatible containers, covering the C6g, M6g, and C7g families.
- The SageMaker Inference Recommender tool can automatically benchmark your model across different instance types to prove the cost-performance gains of Graviton before you commit to a full deployment.
By leveraging machine learning for cloud cost optimization, your teams can identify exactly which parts of an end-to-end pipeline – from data ingestion to real-time inference – are the best candidates for migration to ensure maximum ROI.
Overcoming migration and compatibility hurdles
The primary challenge of adopting Graviton for machine learning is the architectural move to ARM64. If you have legacy x86-specific binaries or proprietary Intel instruction sets, you will likely face multi-architecture support challenges with Graviton. However, for modern stacks using Python, Java, or Go, the transition is usually seamless because these languages have mature ARM64 support.
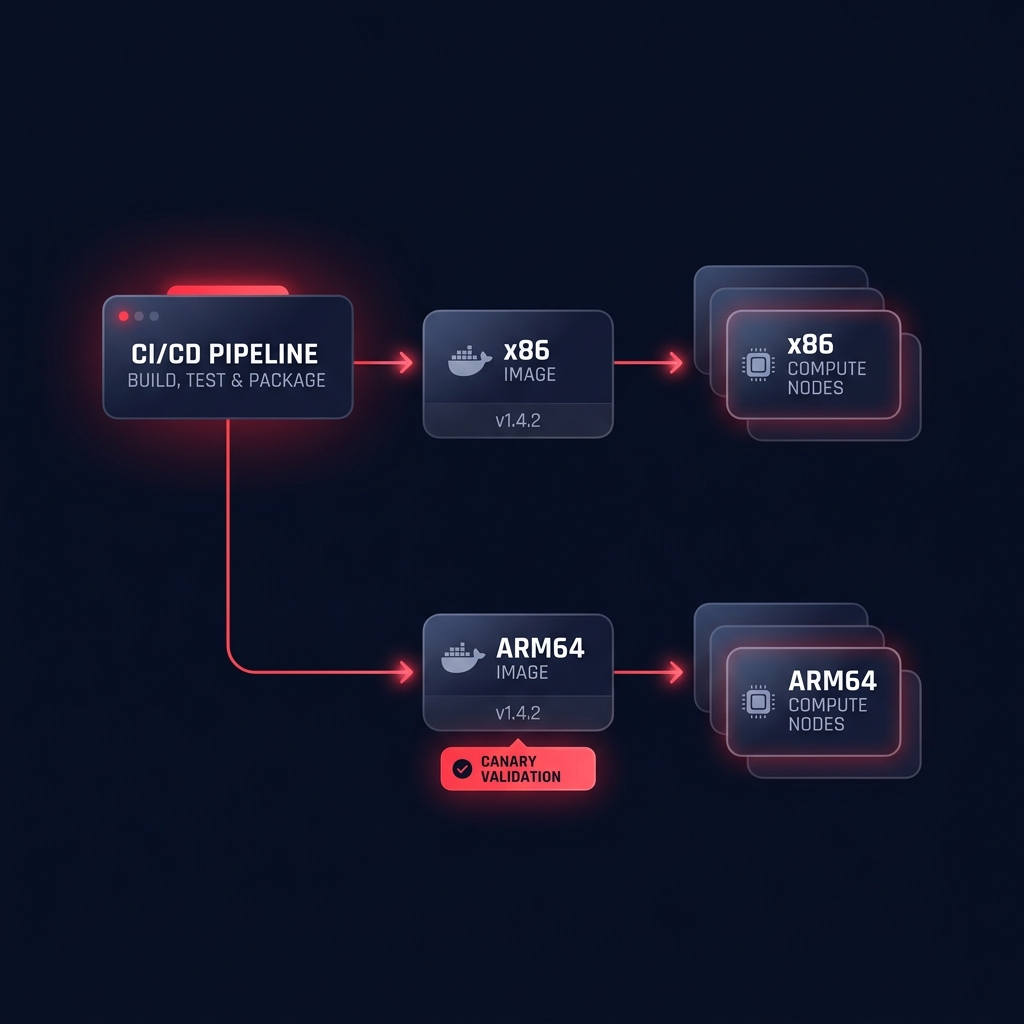
To simplify this process, you should adopt a multi-architecture container strategy. Using Docker and Amazon ECR manifest lists allows your CI/CD pipeline to serve the correct image to both x86 and Graviton nodes automatically. This is particularly useful during a phased migration of applications to Graviton, where you can run a canary deployment to validate performance and accuracy on ARM64 before committing to a full cutover.
Scaling ML workloads without the engineering overhead
Adopting Graviton is one of the most impactful ways to reduce your AWS bill, but it should not require your data scientists to become infrastructure experts. At Hykell, we provide AWS rate optimization that works on autopilot to handle the complexities of infrastructure management for you. Our platform analyzes your machine learning workloads in real-time, identifying the best candidates for Graviton migration and managing your Savings Plans and Reserved Instances to maximize every dollar spent.
We help businesses reduce their cloud costs by up to 40% automatically, ensuring you never pay for unoptimized compute or underutilized resources. Because we only take a slice of the money we save you, there is zero risk to your bottom line.
Ready to see how much your machine learning infrastructure could save? Use our cloud cost calculator to discover your optimization potential today.

