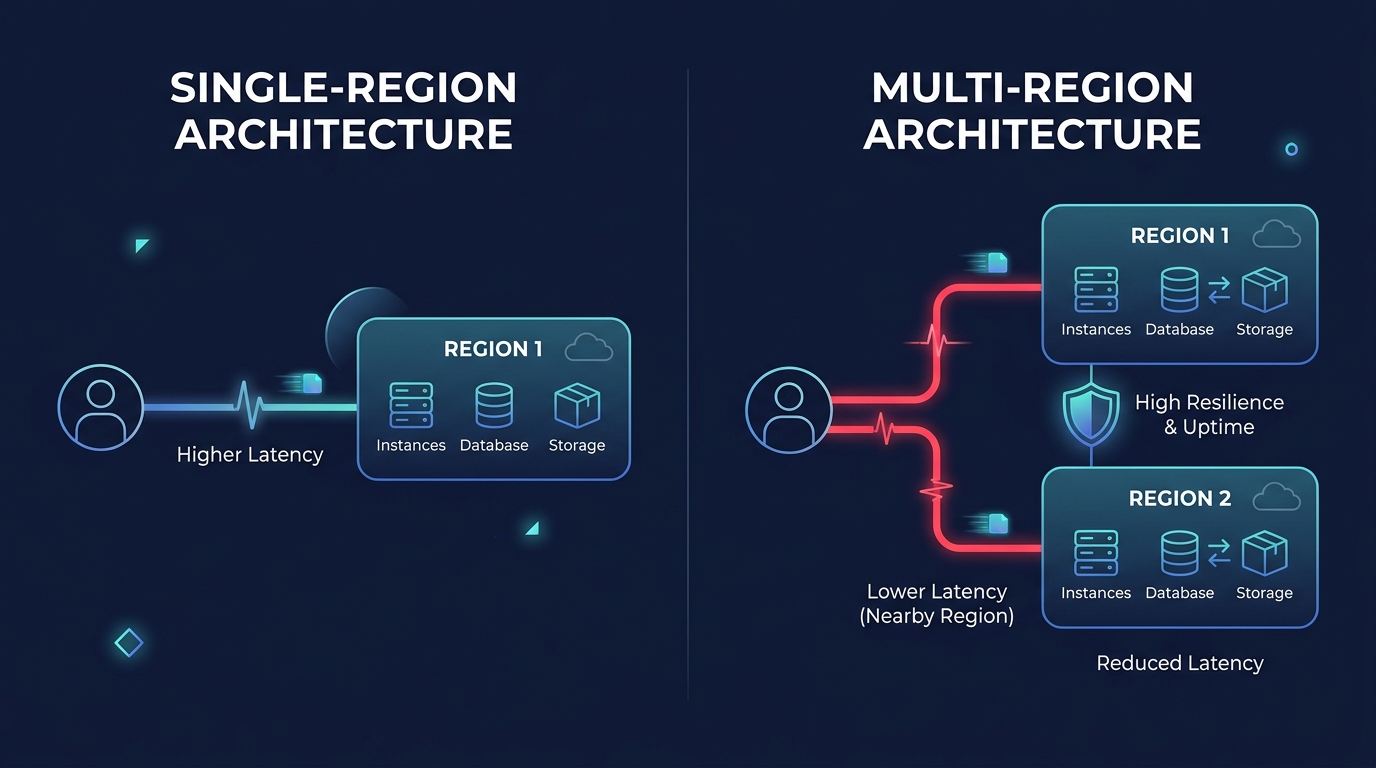
Is your disaster recovery strategy a business insurance policy or a budget black hole? The pursuit of “five nines” availability often leads to multi-region architectures that double infrastructure spend without delivering a proportional return on resilience or global user experience.
Deciding between a robust single-region Multi-AZ setup and a complex multi-region deployment is one of the most consequential architectural choices you will make. While a single-region setup is often sufficient for maintaining a 99.99% uptime, multi-region expansion is frequently driven by strict regulatory requirements or the need for ultra-low latency for a global user base. Understanding the financial friction of geo-redundancy is essential to ensure your AWS performance SLA aligns with your bottom line.
The performance-resilience paradox
The primary drivers for multi-region architectures are lower latency and higher availability. By placing compute resources closer to end-users via Route 53 latency-based routing or AWS Global Accelerator, you can significantly reduce the delays inherent in transcontinental data travel. For mission-critical systems, multi-region setups offer a Recovery Time Objective (RTO) of less than 15 minutes and a Recovery Point Objective (RPO) of under an hour. This provides a safety net that a single region – even with multiple Availability Zones – cannot match.
These gains come at a steep premium. An active-active multi-region architecture requires full infrastructure duplication, including EC2 fleets, RDS instances, and S3 storage. Even an active-passive “pilot light” approach requires cloud latency reduction techniques such as constant data synchronization. This synchronization quietly inflates your monthly bill through inter-region data transfer fees and the cost of keeping secondary resources in a ready state.
The hidden cost drivers of geo-redundancy
When moving beyond a single region, your cost profile shifts from static resource provisioning to dynamic operational expenses. Inter-region data transfer is a primary culprit. While intra-region traffic between AZs costs roughly $0.01/GB in each direction, moving data between regions typically jumps to $0.02–$0.05/GB depending on the specific region pairs. For data-heavy applications, these AWS egress costs can represent up to 35% of your total cloud spend, significantly impacting the ROI of your global expansion.

Data replication overhead further compounds these expenses. Services like Aurora Global Database or RDS Cross-Region Read Replicas simplify management but incur the cost of the secondary instance and the continuous data transfer fees required for synchronization. Additionally, networking components like NAT Gateways introduce processing fees of $0.045 per GB. In a multi-region setup, you often find yourself paying for these gateways in every region and AZ. To mitigate this, you should prioritize VPC Endpoints to eliminate processing fees for AWS service traffic, providing a necessary reprieve for your budget.
Observability at scale also becomes more expensive in distributed environments. Monitoring a multi-region architecture requires cloud application performance monitoring that scales with your infrastructure. CloudWatch Logs and metrics often scale linearly with the number of regions, and for many organizations, observability can account for 25% to 35% of their total AWS spend. Maintaining visibility is necessary, but it requires careful tuning to avoid the trap of “monitoring the monitor” costs.
Multi-AZ as the cost-effective middle ground
For many organizations, the resilience provided by a single-region, Multi-AZ architecture is the ideal balance between cost and performance. By spreading workloads across two or three AZs, you protect against data center failures while avoiding the complexity of inter-region replication. This approach utilizes the AWS backbone for low-latency, high-bandwidth communication at a fraction of the cost of multi-region deployments.
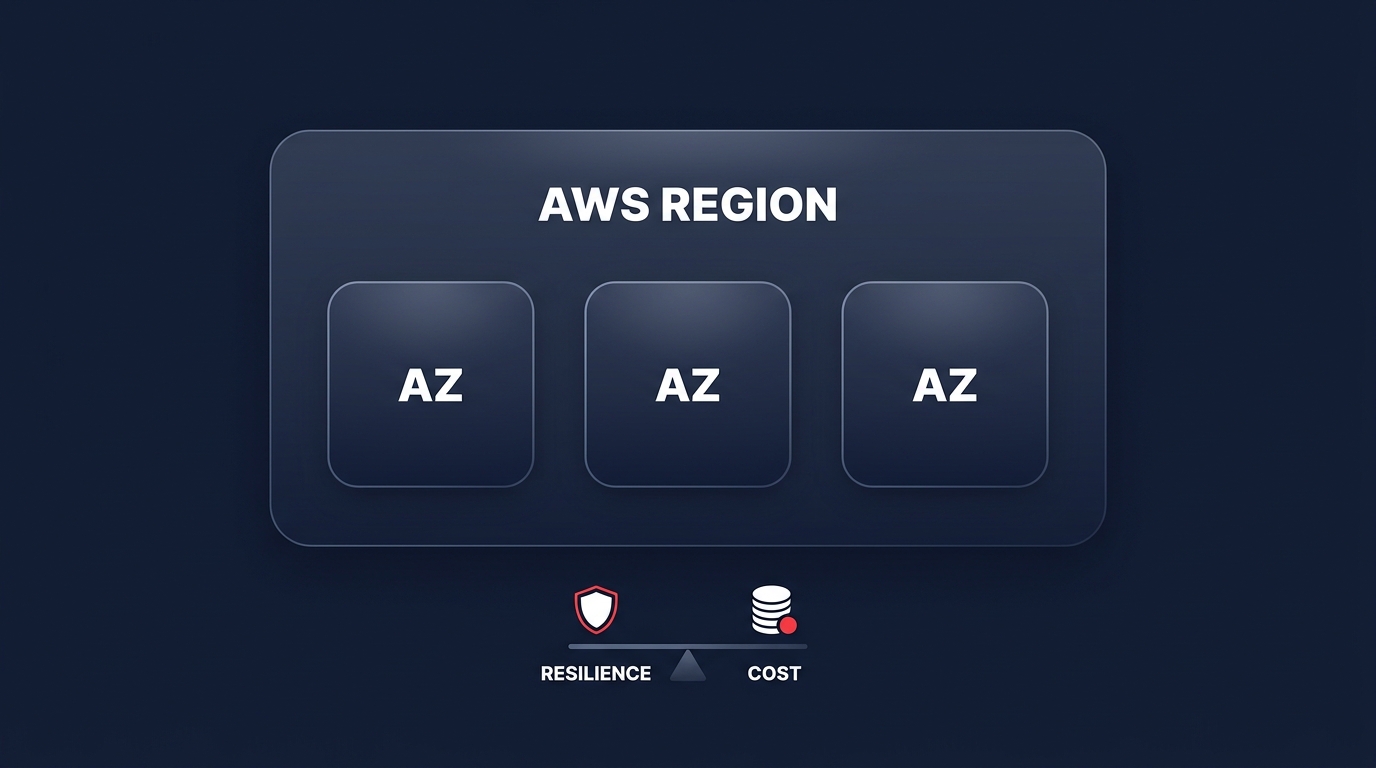
If your workload can tolerate a 1–4 hour RTO, staying within a single region allows you to focus on AWS network performance monitoring to optimize existing traffic. You can further reduce costs by co-locating resources within the same AZ where possible. However, this must be balanced against your availability targets to ensure you do not create a single point of failure within a region.
Strategic optimization of multi-region footprints
If multi-region is a non-negotiable requirement for compliance or performance, optimization becomes a game of architectural efficiency. Instead of replicating your entire stack, consider using Amazon CloudFront to cache content at edge locations. This can reduce the need for regional compute clusters and lower inter-region transfer fees by serving traffic closer to the user without backend intervention.
Managing the “rate” side of the equation is equally vital. Because multi-region deployments involve more idle or standby capacity, leveraging an automated AWS rate optimization strategy ensures you aren’t paying on-demand prices for your disaster recovery infrastructure. By intelligently blending Reserved Instances and Savings Plans, you can maintain high availability without the double price tag.
Hykell provides the observability and automation needed to navigate these complex trade-offs. Our platform dives deep into your cross-region traffic and resource utilization to uncover hidden savings, typically reducing total AWS spend by up to 40% without requiring engineering effort. We operate on a “no save, no pay” model, meaning we only take a slice of the actual savings we generate for your business. To see exactly how much you could save on your current AWS architecture, use our cloud cost savings calculator to get an instant analysis of your optimization potential.

