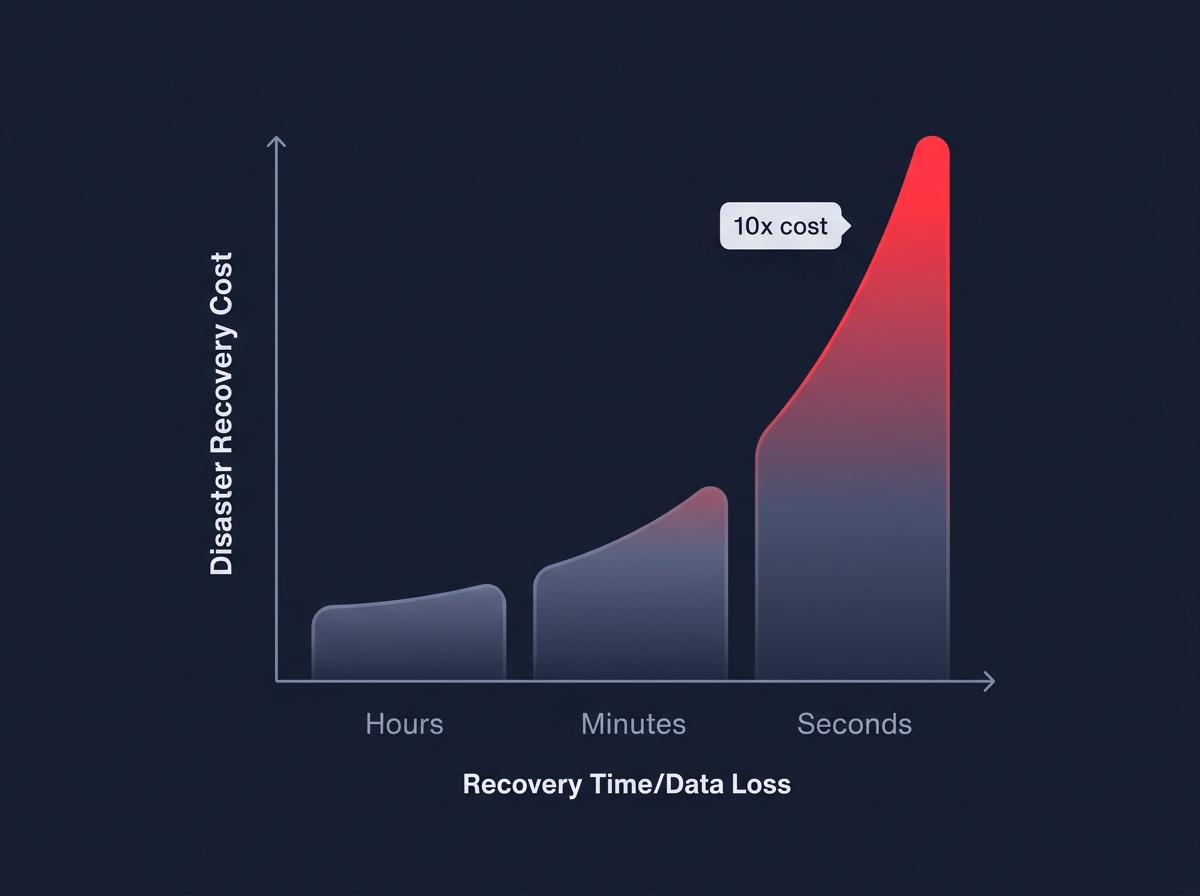
Is your disaster recovery plan protecting your uptime or just draining your budget? While an average US outage can cost $9,000 per minute, over-provisioning for a “zero-downtime” scenario you do not actually need is one of the fastest ways to inflate your AWS bill.
Effective disaster recovery (DR) is not about achieving the lowest possible recovery time; it is about finding the point where the cost of a potential outage intersects with the cost of maintaining a standby environment. For technical managers, this requires a deep dive into the trade-offs between Recovery Time Objectives (RTO), Recovery Point Objectives (RPO), and the architectural tiers AWS provides.
The price of speed: understanding RTO and RPO
The two primary metrics governing your DR spend are RTO and RPO. RTO is the maximum tolerable duration of an outage, while RPO defines the maximum window of data loss you can accept. These objectives dictate your underlying architecture, and the relationship between performance and price is often exponential rather than linear. Industry benchmarks indicate a 10x cost jump when moving from a recovery window of hours to one of seconds.
For example, a strategy using Amazon S3 and EBS snapshots is highly cost-effective but may result in an RTO of over 24 hours. Conversely, multi-site active/active strategies provide near-zero RTO and RPO but typically double your infrastructure costs because they require full duplication across multiple Regions. To avoid unnecessary spend, you should categorize your workloads based on criticality. Aligning these tiers with your AWS performance SLAs ensures you are paying for the resilience your business actually requires without over-provisioning for low-priority services.
Mapping AWS disaster recovery strategies to your budget
AWS identifies four primary DR patterns, each with distinct cost implications. The most economical approach is backup and restore, where you leverage services like AWS Backup to manage snapshots and versioning. While storage costs are low, the time required to provision new infrastructure from these backups can exceed 24 hours. For slightly more critical needs, the pilot light strategy keeps a minimal version of your core requirements – typically your databases – running in a secondary Region. This usually costs between 20% and 30% of your primary environment’s spend because compute resources like EC2 instances remain off until needed.
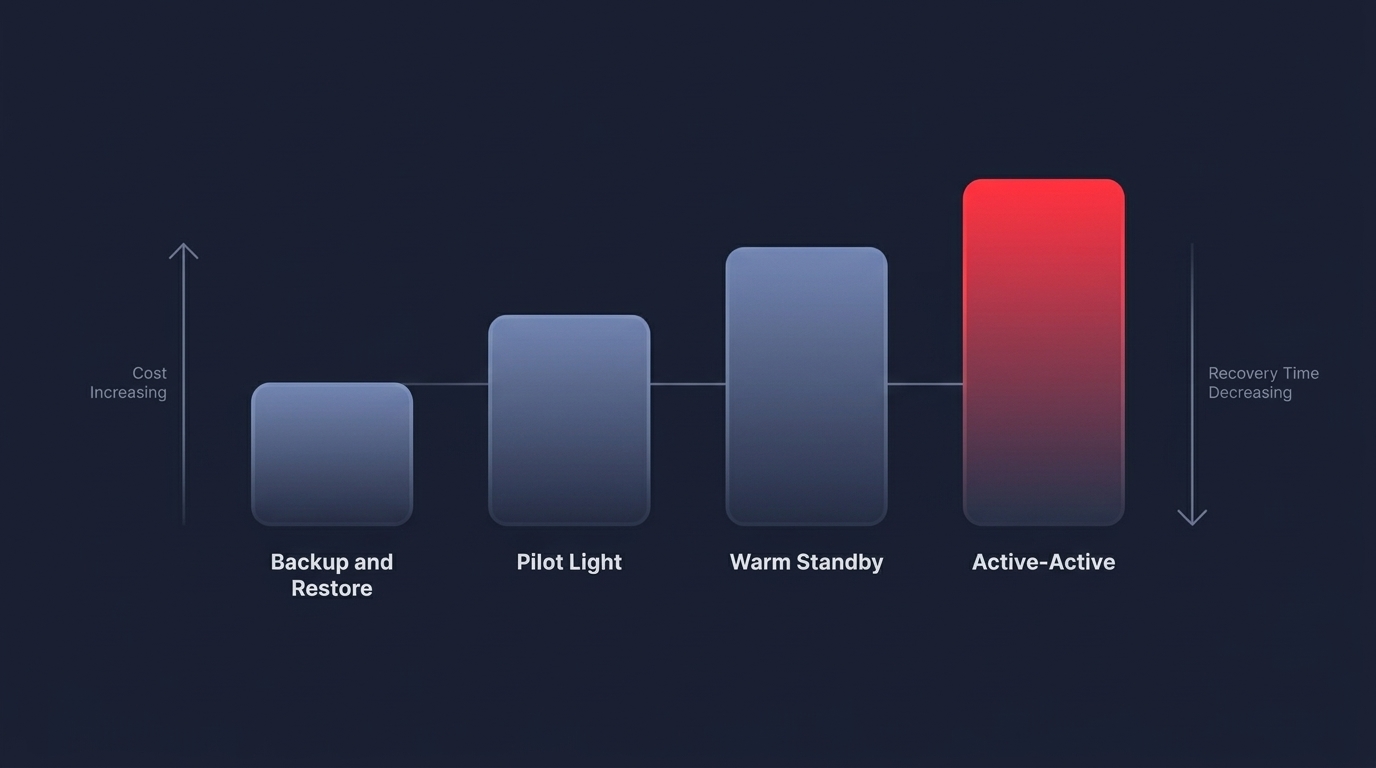
As requirements tighten, you may consider a warm standby, which involves a scaled-down but functional version of your environment that runs continuously. This model can handle a small amount of traffic and scale up rapidly, though you should expect it to cost between 50% and 70% of your primary production environment. At the highest level, multi-site active/active architectures distribute traffic across two or more Regions simultaneously. This offers the highest level of availability but is the most expensive due to data replication and dual-region compute costs. When choosing between these, you should use comparative cost strategies for cloud providers to evaluate how different storage tiers and geographic locations impact your total cost of ownership.
Optimizing data replication and egress
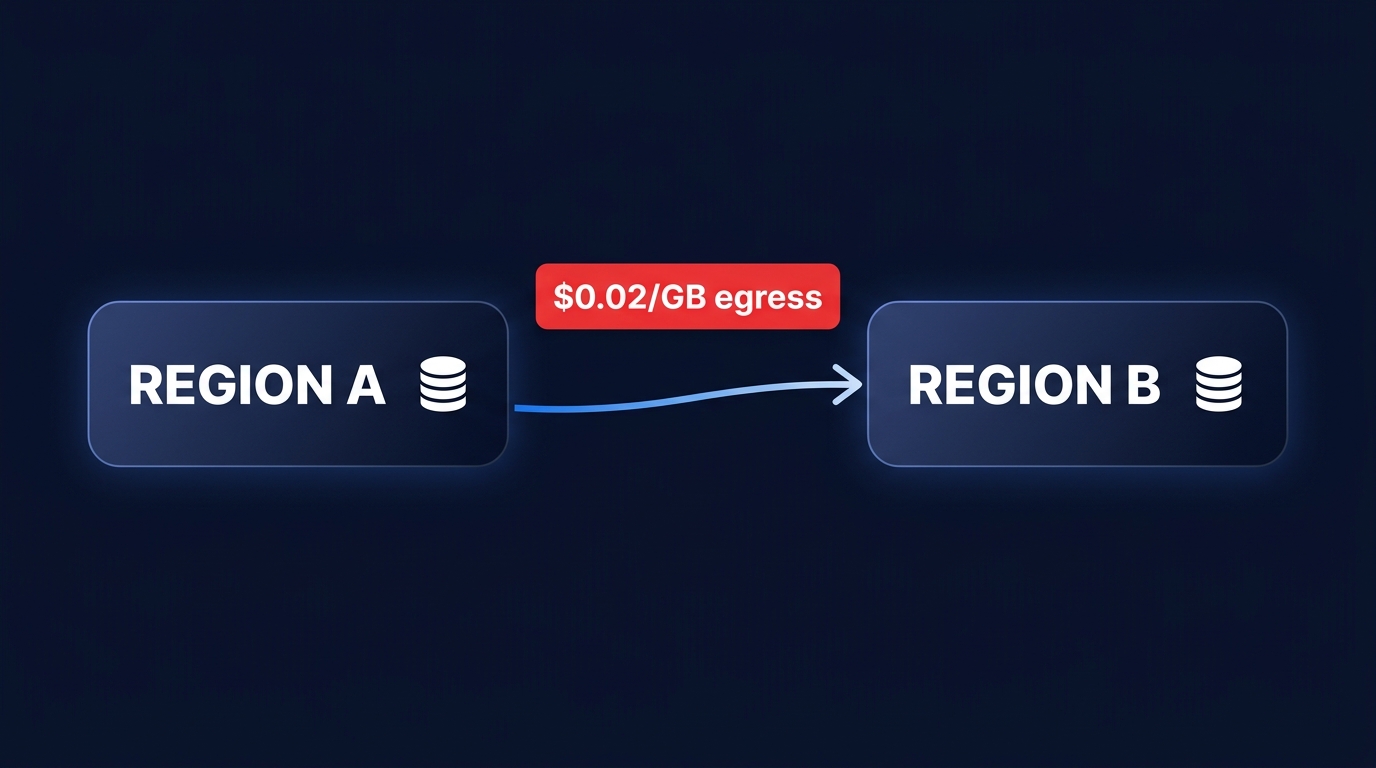
Replication is the backbone of disaster recovery, but it is also a major source of hidden AWS egress costs. Every gigabyte of data sent between AWS Regions incurs transfer fees, which typically hover around $0.02 per GB. For data-heavy applications, these fees can represent 25% to 35% of the total DR budget. To minimize these expenses, evaluate your replication methods carefully. While Amazon S3 Cross-Region Replication (CRR) provides near-real-time availability, it requires disciplined management of storage classes to keep costs in check.
Database replication presents similar challenges. Managing AWS RDS read replica performance is essential for DR, but cross-region replicas introduce both replication lag and transfer costs. Utilizing Aurora Global Database can reduce this lag through shared storage, though it comes at a higher monthly price point for the storage volume. Beyond data transfer, storage management remains a critical pillar of AWS cost management best practices. Regularly deleting obsolete snapshots and using lifecycle policies to move older backups to S3 Glacier can significantly reduce your monthly storage bill without compromising your RPO.
Strategic cost reduction through automation
Managing DR costs manually is often ineffective because cloud environments change too quickly for static spreadsheets to keep up. This is where automated AWS rate optimization becomes invaluable. By automating the mix of Savings Plans and Reserved Instances across both your primary and DR environments, you can ensure you are always receiving the highest possible discount – often up to 72% off compute – without the risk of paying for unused capacity if your architecture shifts.
Hykell specializes in this level of precision by providing a platform that operates on autopilot. By implementing real-time cloud observability, you gain a granular view of which resources are sitting idle in your DR environment and which are truly necessary for your resilience goals. Our tools identify underutilized instances and storage volumes, allowing you to right-size your standby environment automatically and reduce overall costs by up to 40%.
Optimizing your AWS disaster recovery is not just about cutting costs; it is about making your infrastructure smarter. By tiering your workloads, optimizing your replication paths, and leveraging AI-driven commitment management, you can achieve the RTO and RPO your business demands while significantly lowering your cloud spend. Discover your potential for savings by using Hykell’s cost savings calculator to see how much your current DR and compute strategy could be optimized.

