Are you still paying an “x86 tax” for your web tier? Switching to AWS Graviton can slash compute costs by up to 40% while boosting response times for Node.js, Python, or Java microservices. For engineering leaders, it is the most direct path to scaling efficiency.
The move to Graviton is no longer an experimental project for most engineering organizations; it is a strategic requirement for improving unit economics. AWS’s custom-built ARM64 silicon provides a performance-to-cost ratio that traditional Intel and AMD instances struggle to match in modern, containerized environments. However, moving a production web application requires more than just changing an instance type in a configuration file. It requires a methodical evaluation of architectural tradeoffs and a strategy to manage shifts in your commitment portfolio.
The architectural edge of physical cores
The fundamental reason for the efficiency of these instances lies in their underlying design. Traditional x86 instances typically use hyperthreading, where two virtual CPUs (vCPUs) share a single physical core. This sharing can lead to “noisy neighbor” issues between application threads, causing unpredictable latency spikes. In contrast, Graviton maps one vCPU to one physical core, providing dedicated compute resources for every thread and ensuring more consistent execution.
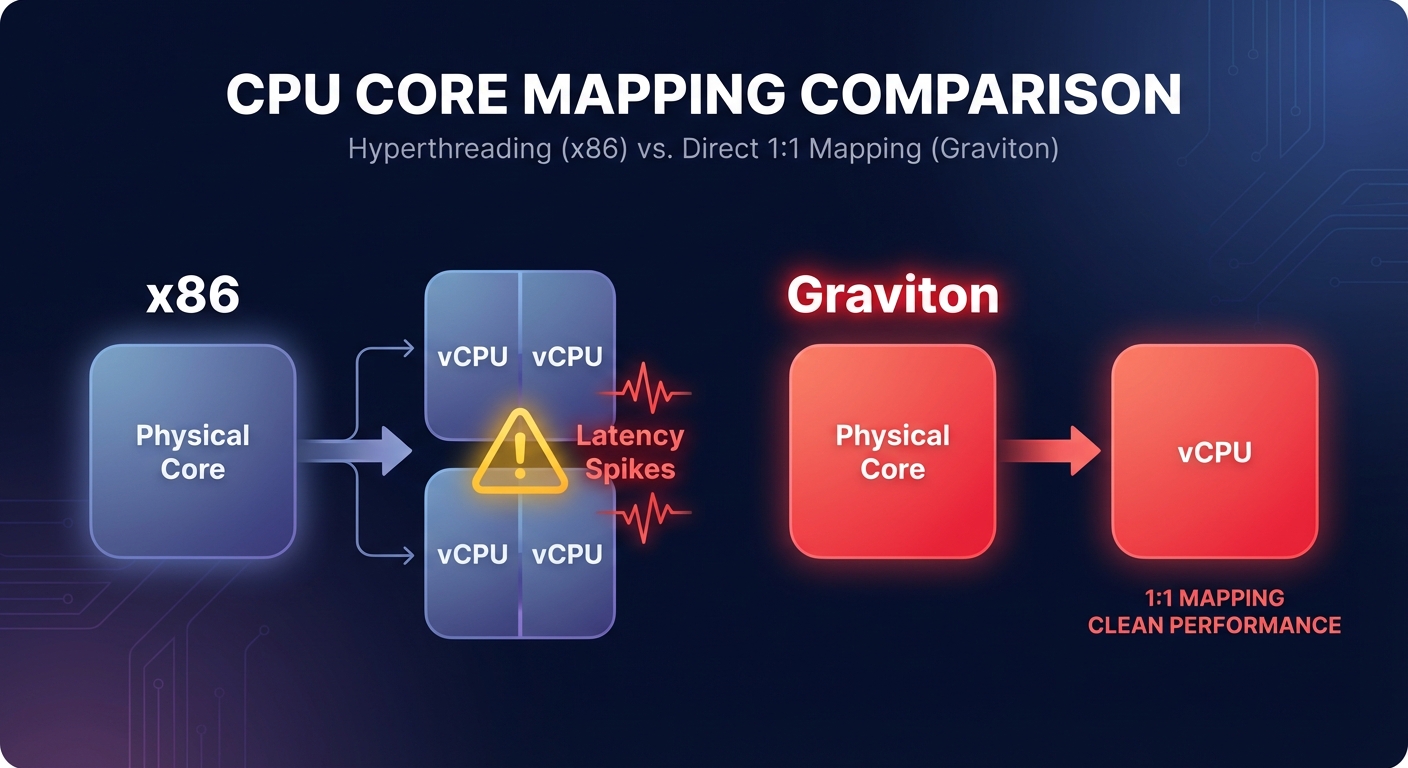
This 1:1 mapping is particularly beneficial for web applications handling high-concurrency workloads where tail latency (P99) is critical. You get higher throughput for both disk- and CPU-bound tasks. Benchmarks show that Graviton3 delivers up to 25% better compute performance and 50% faster memory access than Graviton2. For teams running Nginx, some workloads have seen performance improvements as high as 60%. When you combine these gains with the fact that Graviton instances generally cost 20% less per hour, the total price-performance advantage often exceeds the headline 40% figure.
Evaluating your workload for ARM64 compatibility
Before initiating a migration, you must audit your technology stack for architectural dependencies. Most modern, interpreted languages and runtimes are already “Graviton ready.” Node.js, Python, Go, and Java work seamlessly on ARM64, often requiring nothing more than a fresh build of your container images to achieve full compatibility.
However, certain dependencies can act as blockers that require engineering attention. If your web application relies on legacy x86-only binaries, proprietary Intel instruction sets, or runs on Windows Server, Graviton is not currently a viable option. For Linux-based workloads, you should verify that your base images and third-party monitoring agents have ARM64 versions available. A common oversight is the build environment itself; you must ensure your build pipeline is configured to produce multi-architecture Docker images using tools like Docker Buildx.
A phased migration pattern for engineering teams
Migrating a high-traffic web application should follow a low-risk, phased approach to ensure stability. A typical migration timeline ranges from 9 to 12 weeks, starting with an assessment of low-risk stateless workloads before moving toward more complex stateful systems.
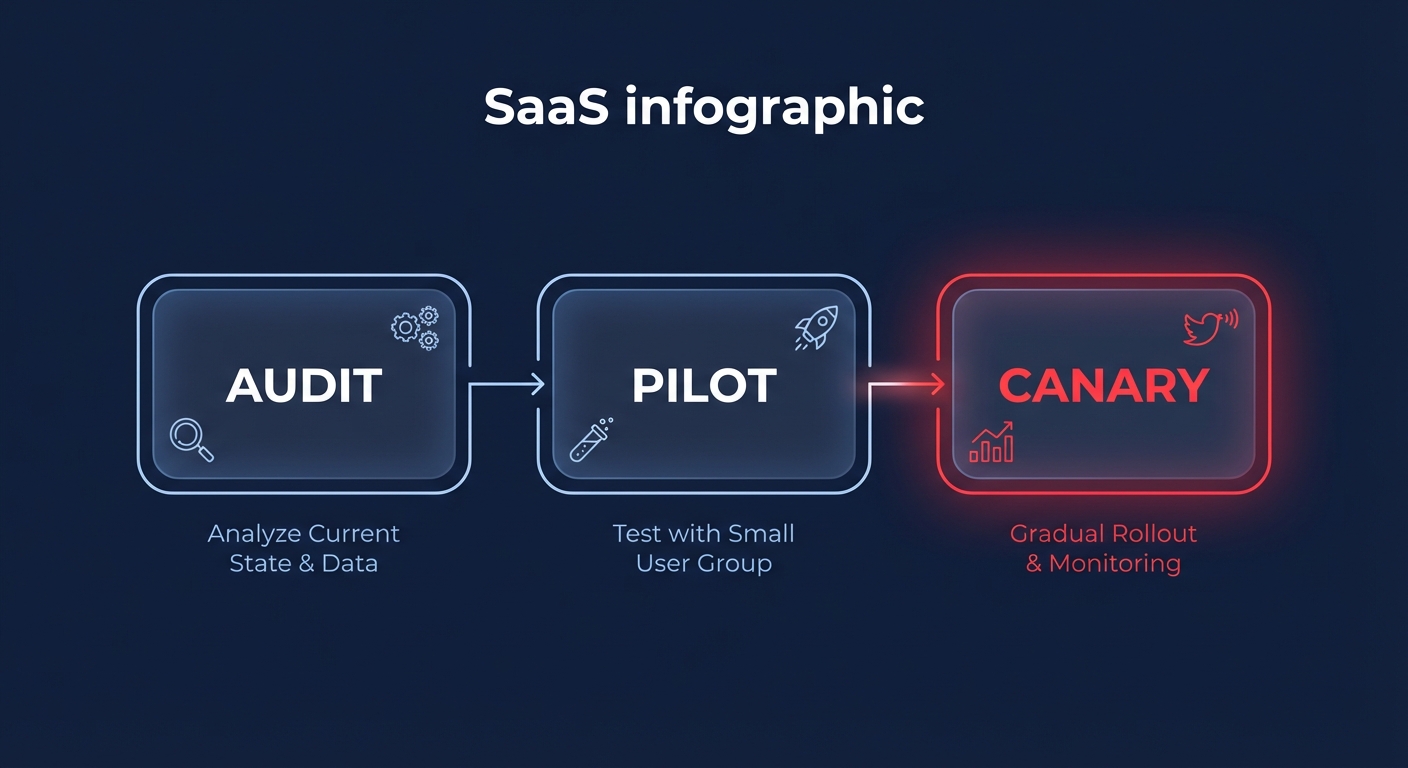
- Start by running a pilot of your microservices on Graviton instances in a staging environment. Use simulation tools to mirror production traffic and compare the P99 latency against your current x86 baseline to validate performance claims.
- Update your infrastructure-as-code templates and Launch Templates to support ARM64 Amazon Machine Images (AMIs). Implementing a mixed-instance policy in your Auto Scaling Groups can prioritize Graviton while allowing for x86 fallbacks if regional capacity becomes constrained.
- Deploy the Graviton-based instances to production using a canary or blue-green strategy. Route a small portion of traffic to the new instances and monitor CloudWatch metrics closely for any unexpected spikes in error rates or memory pressure.
- Once the performance is validated, gradually shift the remaining traffic. This transition period is the ideal time to upgrade EBS volumes from gp2 to gp3, which provides compounding savings and performance boosts alongside the processor migration.
FinOps considerations: managing the savings
From a FinOps perspective, Graviton adoption changes the fundamental math for your discount coverage. Because Graviton uses a different architecture, existing x86-specific Reserved Instances will not apply to your new fleet. However, Compute Savings Plans are flexible and automatically cover Graviton instances across EC2, Lambda, and Fargate, providing discounts of up to 72%.
To maximize these gains, teams must avoid the “set it and forget it” trap. As you scale out your ARM64 fleet, your usage patterns will shift, potentially leaving you with underutilized x86-specific commitments. This is where real-time observability becomes critical for maintaining a high Effective Savings Rate (ESR). You need to ensure your commitment coverage aligns perfectly with your new architectural footprint to prevent waste.
Accelerate your Graviton gains with Hykell
While the benefits of switching are clear, the manual effort required to benchmark, plan, and monitor a fleet-wide migration can overwhelm lean engineering teams. Hykell is designed to accelerate your Graviton gains by automating the heavy lifting of cloud cost optimization.
Hykell’s platform performs continuous workload compatibility assessments to identify exactly which of your instances are ready for ARM64 today. Once you decide to migrate, Hykell’s automated rate optimization handles the complexity of commitment management. We ensure that your Graviton savings stack on top of your existing Savings Plans without the risk of over-provisioning or the need for manual forecasting.
Beyond the initial migration, Hykell provides live monitoring and reporting that offers deeper insights than standard native tools. We track the real-world impact of your architectural changes on your bottom line, helping you maintain significant compute reductions on autopilot. Hykell operates on a success-only model, meaning we only take a slice of what you save. If we do not uncover actionable savings, you do not pay.
Ready to see how much your web application could save by moving to custom silicon? Explore Hykell’s automated cost optimization today and put your cloud savings on autopilot.