Are you still defaulting to Intel for your EC2 instances? While x86 is the traditional choice, switching to AWS Graviton can slash your compute costs by 40% while simultaneously increasing your application’s throughput.
For FinOps teams and engineering leaders, the question isn’t just about hourly rates – it is about price-performance. AWS Graviton (ARM64) instances typically cost 20% less per hour than their Intel (x86) counterparts, but the real magic happens when you realize they often deliver 25% better computational performance for the same workload.
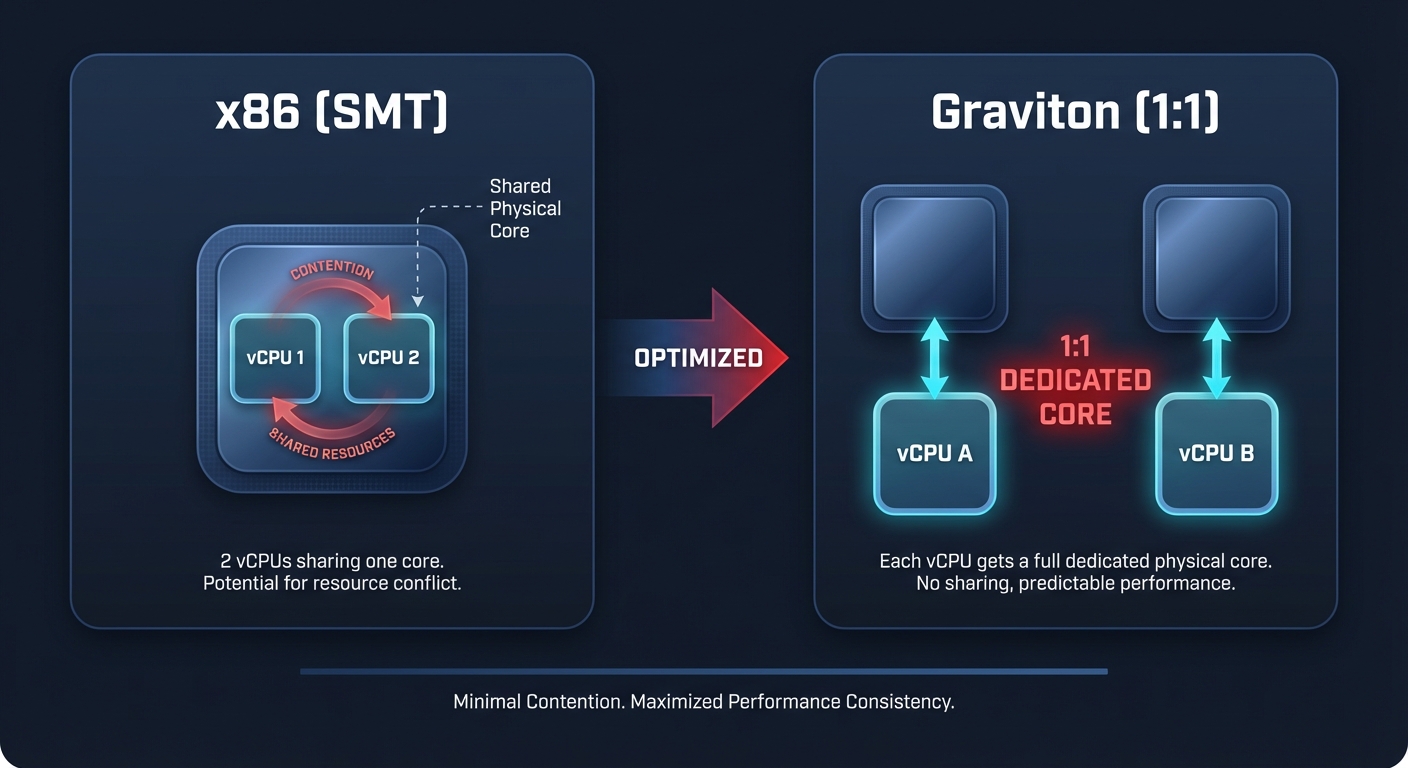
The vCPU secret: Why ARM scales differently
To understand the cost gap, you have to look at the silicon. Traditional x86 processors from Intel and AMD use Simultaneous Multithreading (SMT), often called Hyperthreading. In this model, one physical core is split into two virtual CPUs (vCPUs), which can lead to resource contention. Think of it like two workers trying to use the same narrow desk; they can get a lot done, but they often bump into each other.
AWS Graviton uses a 1:1 vCPU-to-physical-core mapping. This means every vCPU you pay for is a dedicated physical core with its own cache and execution resources. For multi-threaded workloads like web servers or microservices, this architecture provides more consistent performance and eliminates the “noisy neighbor” effect within the processor itself. Furthermore, Graviton3 delivers a massive boost in memory bandwidth – up to 120 GB/s compared to the 60–70 GB/s typically found on Intel Xeon instances – allowing data-heavy applications to breathe.
Benchmarking the performance gap
When we look at cost comparisons between Graviton and Intel, the benchmarks favor ARM for modern, cloud-native tasks. For machine learning, Graviton4 achieved 53% faster XGBoost training times than AMD and 34% faster than Intel. This trend continues into generative AI, where Llama 3.1 8B model inference testing showed Graviton4 delivering 168% higher token throughput than AMD EPYC and 162% better performance than Intel Xeon.
Even foundational tasks like data compression see a boost, as Graviton4 consistently outperforms AMD Genoa and Intel Sapphire Rapids in 7-Zip benchmarks. Beyond pure speed, these efficiencies translate directly to your bottom line. Research indicates that Graviton4 reduces compilation costs by approximately 35% compared to x86 alternatives. In a real-world scenario, a compute-heavy workload that costs $182,000 annually on Intel can often run for just $91,000 on Graviton – a staggering 50% reduction when you factor in both lower hourly rates and increased efficiency.
AWS Lambda: Graviton vs. x86
For serverless fans, the choice is even simpler. AWS Lambda functions powered by Graviton2 or Graviton3 are priced roughly 20% lower than x86 equivalents. Because Lambda scales CPU power linearly with memory, many Lambda cost reduction techniques involve moving to ARM to capture these structural savings.
For instance, an e-commerce order processing function might run for 400ms on a 256MB x86 Lambda. By switching to a 1024MB Graviton Lambda, you might reduce the duration to just 80ms. Even though you allocated more memory, the speed boost combined with the lower ARM pricing results in a 22% total cost reduction per invocation. This “faster is cheaper” logic applies to any CPU-bound task, from image processing to JSON transformation.

When x86 still makes financial sense
Despite the high performance-to-dollar ratio, Graviton isn’t a silver bullet for every use case. You should generally stick with Intel or AMD – the latter of which is typically 10% cheaper than Intel – if your environment requires Windows Server. Currently, Graviton is a Linux-only playground, making it incompatible with Windows-dependent stacks.
Legacy binaries also present a challenge. If your application relies on proprietary x86-only binaries or specialized Intel instruction sets like AVX-512 that have not been ported to ARM, the effort of emulation often negates the cost savings. Finally, for certain legacy applications that cannot take advantage of multiple cores, Intel’s raw single-threaded performance may still win on pure latency, even if the overall price-performance ratio is technically worse.
Accelerate your transition with Hykell
The biggest barrier to Graviton adoption isn’t performance – it’s the engineering effort required to identify compatible workloads and benchmark them accurately. Manually migrating applications to Graviton can take months of trial and error as you audit dependencies and rebuild container images.
Hykell removes the guesswork by accelerating your Graviton gains through intelligent automation. Our platform analyzes your entire environment to identify low-risk, high-reward migration candidates – like stateless web tiers and containerized microservices – on autopilot. We don’t just suggest the move; we help you layer Graviton’s structural savings on top of automated rate optimization to ensure you are always running on the most cost-efficient architecture.
Most Hykell clients see a 40% reduction in their AWS bill without their engineers having to manually right-size a single instance. If you are ready to see how much you could save by making the switch, Check out our pricing. We only take a slice of what we save you – if you don’t save, you don’t pay.