Is your Amazon ElastiCache bill growing faster than your application’s user base? While in-memory databases deliver sub-millisecond latency, they often become one of the most expensive line items on an AWS invoice if left unmanaged.
Upgrade to Graviton-based instances
One of the simplest ways to instantly improve your price-to-performance ratio is migrating to AWS Graviton-based nodes, such as the M6g or R6g families. These ARM-based instances typically offer a 5% lower cost compared to their x86 counterparts while delivering significantly higher throughput. You can think of this as an engine swap for your caching layer; by moving to more efficient hardware, you get more power while consuming fewer resources.
Extensive performance benchmarking for AWS Graviton instances shows that moving to Graviton can result in up to 40% to 60% better price-to-performance for memory-bound workloads like Redis. Because ElastiCache supports online scaling, you can often switch node types with minimal downtime. This allows you to benefit from these architectural efficiencies without a major refactor or long maintenance windows.
Leverage reserved nodes and savings plans
If your caching layer runs continuously, paying on-demand rates is a luxury you cannot afford. ElastiCache reserved nodes allow you to commit to a specific instance type for a one- or three-year term in exchange for substantial discounts. According to the Amazon ElastiCache pricing details, a one-year commitment typically saves around 32%, while a three-year commitment can slash costs by up to 60% compared to on-demand pricing.
Furthermore, Amazon ElastiCache is now included in AWS Savings Plans, providing a more flexible alternative to traditional reserved nodes. This model allows you to commit to a specific hourly spend across different instance families and regions, offering protection against over-provisioning if your architectural needs change. At Hykell, we specialize in automating rate optimization so you never pay a premium for predictable, steady-state workloads.

Implement data tiering for large datasets
Not all data stored in your cache needs to live in expensive DRAM. For clusters exceeding several hundred gigabytes, consider using ElastiCache Data Tiering with R6gd nodes. These instances utilize local NVMe SSDs to store less frequently accessed data while keeping “hot” data in memory. This is similar to moving seasonal items to a basement or attic; they are still accessible, but they don’t take up the limited space in your primary living area.
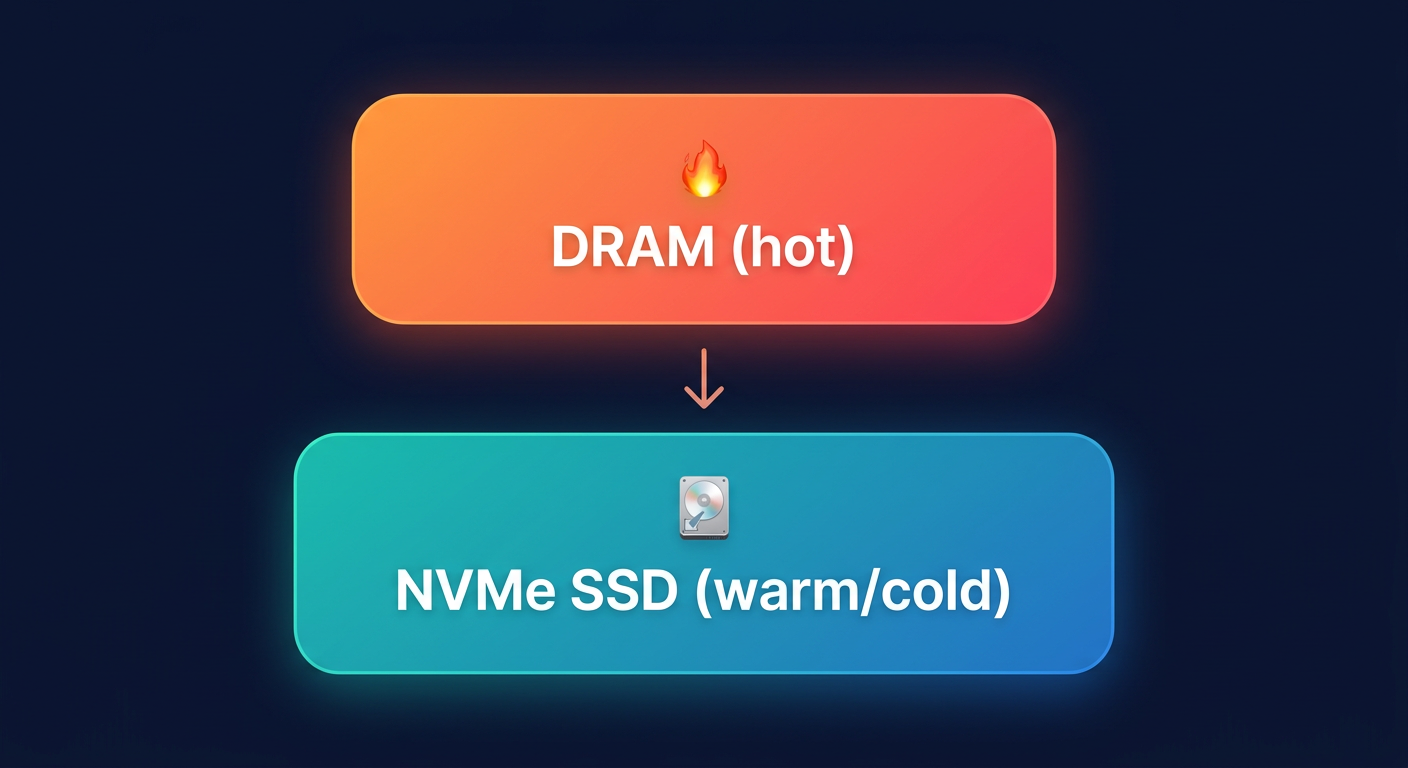
Data tiering is most effective when less than 20% of your dataset is accessed frequently. By offloading the remaining 80% to SSDs, you can achieve significant savings compared to scaling out memory-only clusters. A technical analysis of Redis workloads suggests that this approach can reduce costs by over 50% for large-scale deployments, allowing you to maintain capacity in the hundreds of terabytes while preserving the low-latency benefits of a managed service.
Right-sizing through metric analysis
Over-provisioning is the primary driver of wasted cloud spend, yet many teams keep excess capacity “just in case.” To right-size effectively, you must monitor specific CloudWatch metrics like `DatabaseMemoryUsagePercentage` and `CPUUtilization`. AWS best practices suggest targeting a 70% to 80% utilization rate for autoscaling while maintaining a 25% memory headroom to handle background operations like snapshots and synchronization.
If your CPU utilization remains consistently low, you may be able to consolidate your cluster or move to smaller node sizes to reduce your footprint. Conversely, if your eviction rate is high, your nodes are likely too small for your data volume, which can hurt application performance and increase latency. Implementing cloud resource right-sizing techniques ensures your infrastructure scales dynamically with demand, preventing the “set-it-and-forget-it” trap that leads to inflated monthly bills.
Optimize networking and engine versions
Data transfer costs are frequently overlooked in ElastiCache deployments but can quickly add up. AWS charges approximately $0.01 per GB for cross-AZ traffic within a region. To minimize these fees, you should ensure your application instances, whether they are running on EC2, EKS, or Lambda, are located in the same Availability Zone as your primary ElastiCache nodes whenever possible. Aligning your network architecture in this way removes the “hidden tax” of cross-AZ communication.
Upgrading to the latest engine versions also yields technical dividends. For example, Redis 7 introduced enhanced I/O multiplexing, which can boost throughput by up to 72%. This increased efficiency often allows you to handle the same request volume with fewer or smaller nodes, directly reducing your monthly spend. By combining network alignment with the latest engine efficiencies, you create a lean infrastructure that prioritizes both speed and cost-effectiveness.
Managing these technical configurations manually is a full-time job for engineering teams. Hykell provides automated cost optimization that operates on autopilot, helping you uncover hidden savings and optimize your infrastructure without compromising performance. We only take a slice of what you save – if you don’t save, you don’t pay. To see how much you could be saving on your AWS bill, use the Hykell savings calculator or contact us today for a detailed cost audit.