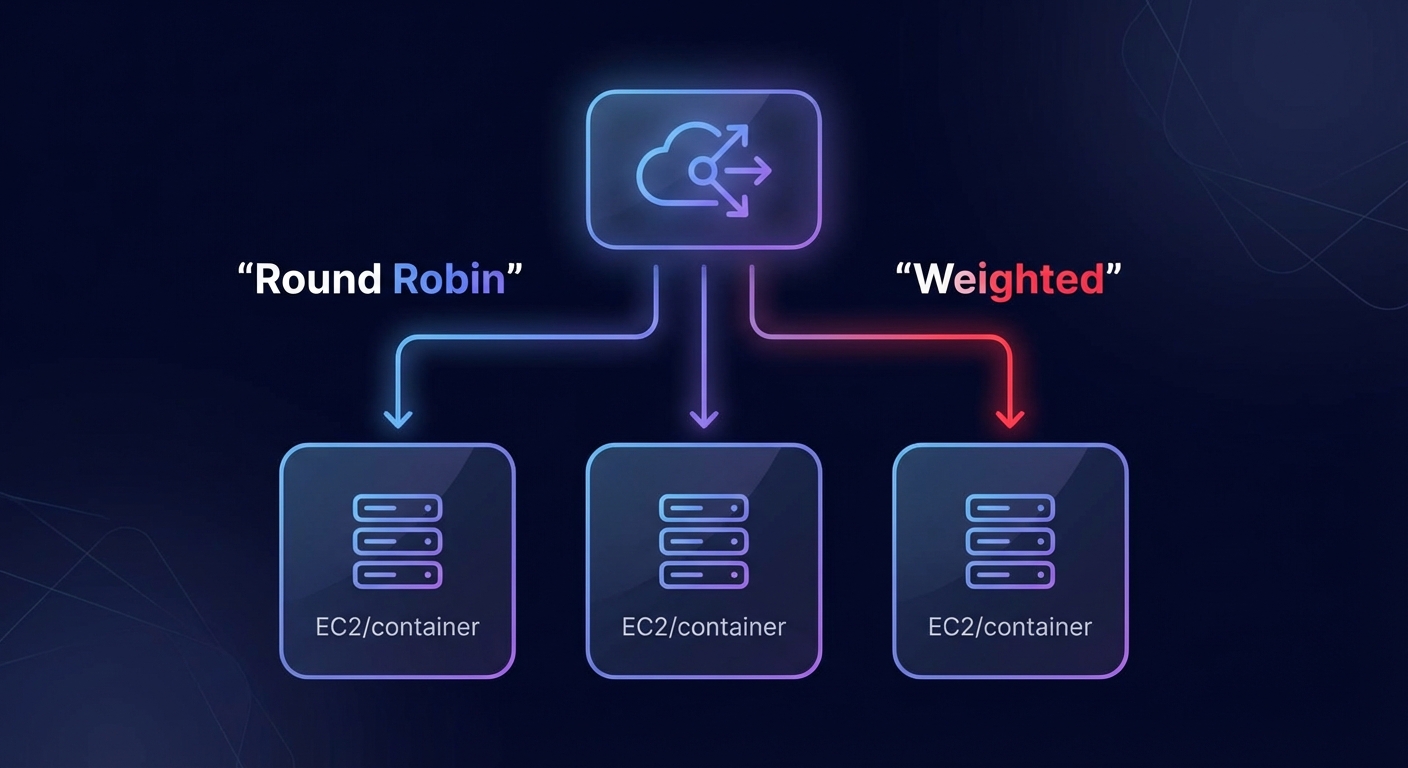
Are you over-provisioning target groups because you’re unsure how traffic is actually distributed? For DevOps leads, choosing the wrong algorithm doesn’t just spike latency – it forces you to run extra instances to handle uneven peaks, leading to significant cloud waste. Here is how to pick the right strategy.
In the AWS ecosystem, Elastic Load Balancing (ELB) serves as the traffic cop for your infrastructure. By effectively distributing incoming application traffic across multiple targets – such as EC2 instances, containers, and Lambda functions – you ensure that no single resource becomes a bottleneck. However, the efficiency of this distribution depends entirely on the algorithm and the load balancer type you select.
The core algorithms of AWS load balancing
The algorithm you choose determines the logic used to pick the next target for a request. While simple methods are the default for many, modern cloud performance benchmarking shows that more sophisticated methods are often required for complex microservices to ensure stability and efficiency.
Round robin and weighted round robin
The round robin method is the most straightforward approach, where the load balancer distributes traffic equally across all healthy servers in a circular order. On AWS, the load balancer nodes typically split traffic equally and then distribute that share across registered targets. This works well when all backend targets have similar compute specifications and the requests require roughly the same amount of processing power.
However, when you are running a mixed fleet – perhaps a combination of older x86 instances and high-performance AWS Graviton processors – standard round robin falls short. Weighted round robin allows you to assign specific weights to servers based on their capacity. This ensures your more powerful nodes handle a larger share of the traffic, preventing them from sitting idle while smaller, less capable nodes struggle to keep up.
Least connections and weighted least connections
If your application handles requests that vary significantly in complexity, the least connection method is often more effective. This algorithm directs traffic to the server with the fewest active connections, which is particularly useful for database-heavy applications or long-running API calls where a single request might hold a connection open for several seconds.
For architectures with heterogeneous server capacities, the weighted least connection method adds another layer of intelligence by considering the capacity of the server alongside the current connection count. This strategy helps you maintain a high AWS performance SLA by preventing “long-tail” requests from stacking up on a single target, which could otherwise lead to localized timeouts and degraded user experiences.
IP hash and resource-based methods
IP hashing uses a mathematical computation on the client’s IP address to map it to a specific server. This is essential for applications requiring session persistence (stickiness), where the client must return to the same backend for a consistent experience, such as during a multi-step checkout process. By keeping the client tied to a specific instance, you avoid the overhead of re-syncing session data across your entire fleet.
More advanced resource-based methods analyze actual server load – such as CPU and memory usage – using specialized agents. This ensures traffic is sent only to servers with the actual compute headroom to handle it. This proactive approach to distribution is a cornerstone of AWS EC2 performance tuning, as it prevents targets from reaching a “saturation point” where performance degrades exponentially.
Choosing the right AWS load balancer type
Your choice of algorithm is often dictated by the specific load balancer type you deploy. These services operate at different layers of the OSI model and are optimized for different traffic patterns. The Application Load Balancer (ALB) operates at Layer 7 and is the primary choice for web applications. It supports content-based routing by URL path or host header and typically sees latencies around 400ms. This flexibility makes it indispensable for Kubernetes optimization on AWS, where complex microservices require precise traffic steering.
For scenarios requiring ultra-low latency and high throughput, the Network Load Balancer (NLB) is the superior choice. Operating at Layer 4, it can handle millions of requests per second while maintaining extremely low latency even during volatile traffic spikes. If you are managing third-party virtual appliances like firewalls or intrusion detection systems, the Gateway Load Balancer (GWLB) operates at Layer 3. It uses a 5-tuple flow hash algorithm and the GENEVE protocol to maintain traffic flow consistency with a latency of approximately 200 microseconds.
Trade-offs between reliability, performance, and scalability
Every balancing strategy involves a cost-performance tradeoff. A strategy that maximizes reliability through redundant target groups might increase your costs, while one focused solely on immediate cost-cutting might negatively impact the end-user experience.
Reliability and health checks
Load balancers improve reliability by removing unhealthy targets from the rotation automatically. By configuring granular health checks, you ensure that traffic only reaches instances that are actually ready to process it. Integrating these checks with AWS EC2 auto scaling best practices allows for seamless self-healing. When a target fails a health check, the load balancer stops sending it traffic, and the Auto Scaling Group (ASG) replaces the instance without any manual intervention required from your DevOps team.
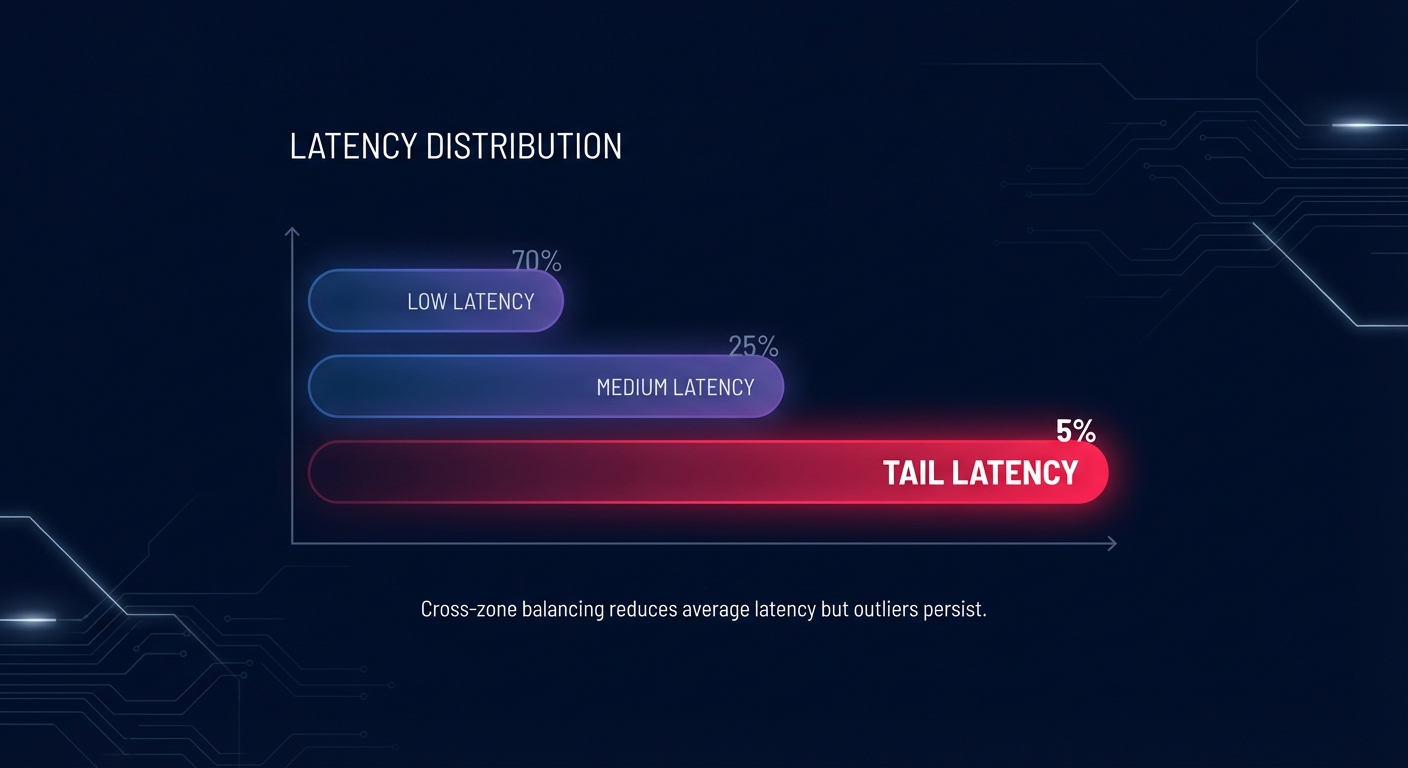
Performance and tail latency
Latency is often the result of “chatty” communication or uneven load distribution across Availability Zones. To reduce tail latency, you should consider enabling cross-zone load balancing. This ensures traffic is distributed evenly across all registered targets in all enabled Availability Zones, rather than just the ones in the same zone as the load balancer node. Implementing this is a critical component of wider cloud latency reduction techniques, as it prevents any single zone from becoming over-utilized while others sit idle.
Scalability and automation
True cloud scalability is the ability to handle growth without manual configuration. By using platform-specific auto-scaling strategies, your load balancer and target groups work in tandem to expand and contract based on real-time demand. However, many organizations suffer from “zombie” infrastructure – idle ALBs that cost roughly $20–30 per month while serving no traffic. Regular audits and robust AWS network performance monitoring are required to ensure your load balancing infrastructure isn’t silently inflating your monthly bill.
Aligning load balancing with cost optimization
Efficiency in load balancing is a primary lever for reducing your overall AWS bill. When traffic is distributed intelligently, you can run your instances at higher average utilization rates (60–80%) rather than keeping them at 20% “just in case” a specific node gets overwhelmed by a poorly distributed burst of requests.

To support a cost-efficient architecture, you must move beyond manual, static configurations. Real-time AWS application performance monitoring provides the granular data needed to right-size your target groups. By understanding your specific traffic patterns, you can more effectively apply AWS rate optimization strategies, such as covering your predictable baseline load with Reserved Instances and using auto-scaling with Spot Instances to handle variable peaks.
At Hykell, we believe that high-performing architecture shouldn’t require an endless engineering tax. Our platform provides automated cloud cost optimization that dives deep into your AWS environment to identify underutilized resources and misconfigured load balancing patterns. By automating the technical debt of infrastructure management – like right-sizing target groups and managing commitment portfolios – Hykell helps organizations reduce their AWS spend by up to 40% while maintaining full compliance and peak performance. If you are ready to see how much you could be saving without touching a single line of code, explore our automated cloud cost optimization services today.

