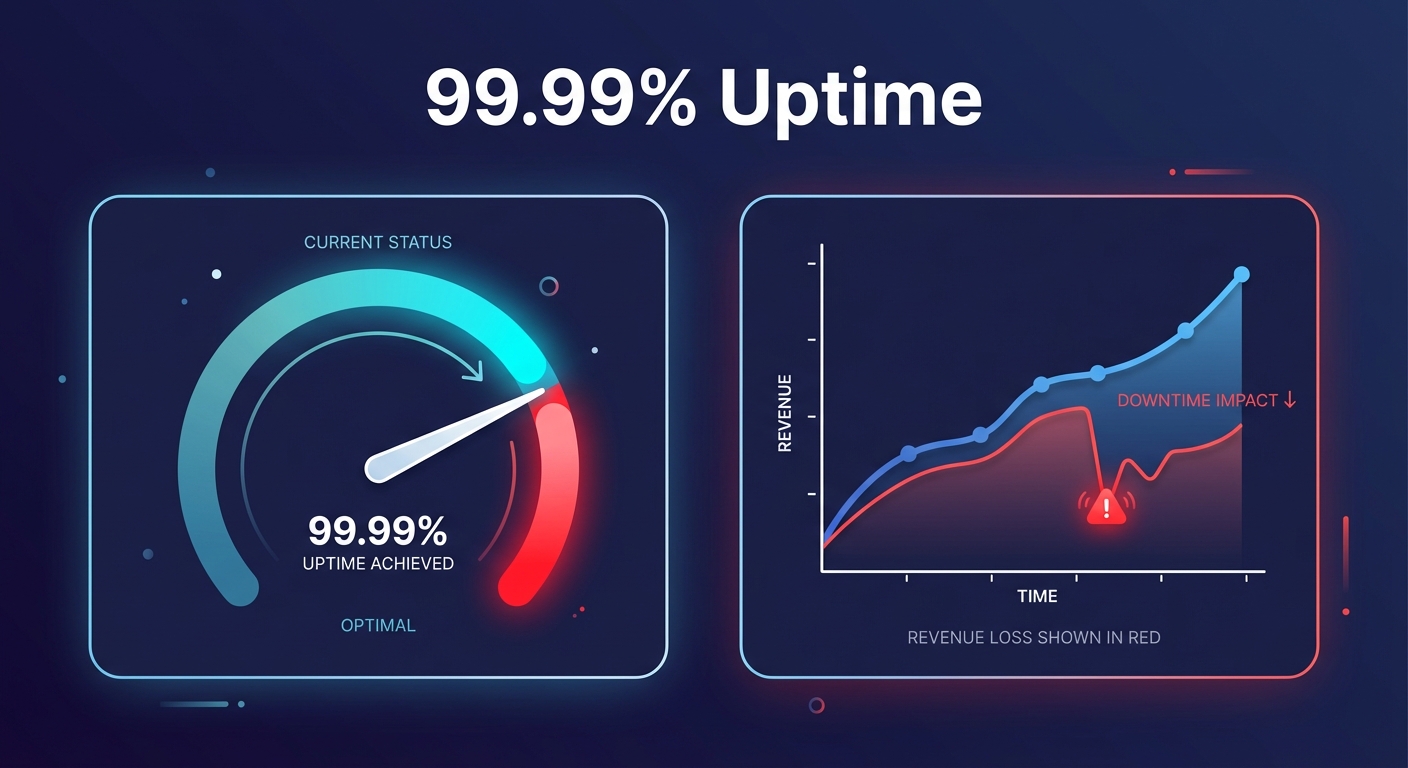
Is your 99.99% uptime guarantee actually protecting your revenue, or is it just a line of fine print in a 50-page legal document? For engineering and finance leaders, understanding the mechanics of these agreements is essential for mitigating risk and avoiding wasted cloud spend.
What is a cloud performance SLA?
A cloud performance SLA is a legally binding contract between a cloud service provider like AWS and you, the customer. It defines the minimum level of service you can expect, typically expressed as a percentage of time the service remains available during a monthly billing cycle. Beyond simple availability, these agreements outline the “remedies” – usually in the form of service credits – that you are entitled to if the provider fails to meet those benchmarks.
For AWS-focused engineering and FinOps leaders, these agreements serve as more than just legal protection; they are the foundation for your cloud performance compliance standards. By quantifying the provider’s commitments, you can better understand your exposure to risk and build resilient architectures that align with your broader business objectives.
How service level commitments work on AWS
AWS currently publishes over 300 separate Service Level Agreements for its paid, generally available services. These commitments typically focus on “Monthly Uptime Percentage,” but the level of protection you receive often depends on your specific architectural choices. For example, the Amazon EC2 Service Level Agreement offers tiered commitments based on how you deploy your resources.
If you deploy instances across two or more Availability Zones within the same region, AWS provides a Region-Level SLA of 99.99%. However, if you choose to run a single instance in isolation, the guarantee drops to 99.5%. When AWS falls below these marks, you can claim service credits that scale with the severity of the outage. A regional uptime between 99.0% and 99.99% may result in a 10% credit, while dropping below 95.0% could entitle you to a 100% credit for that billing cycle. It is important to remember that these credits are not applied automatically. You must proactively monitor CloudWatch metrics and file a formal claim with proof of the breach to recover those costs.

Critical performance metrics for compliance
While uptime is the metric that usually makes the headlines, sophisticated cloud performance monitoring requires tracking a broader set of data points. This ensures your application isn’t suffering from “silent failures” where the service is technically up but performing too poorly to be useful to your customers.
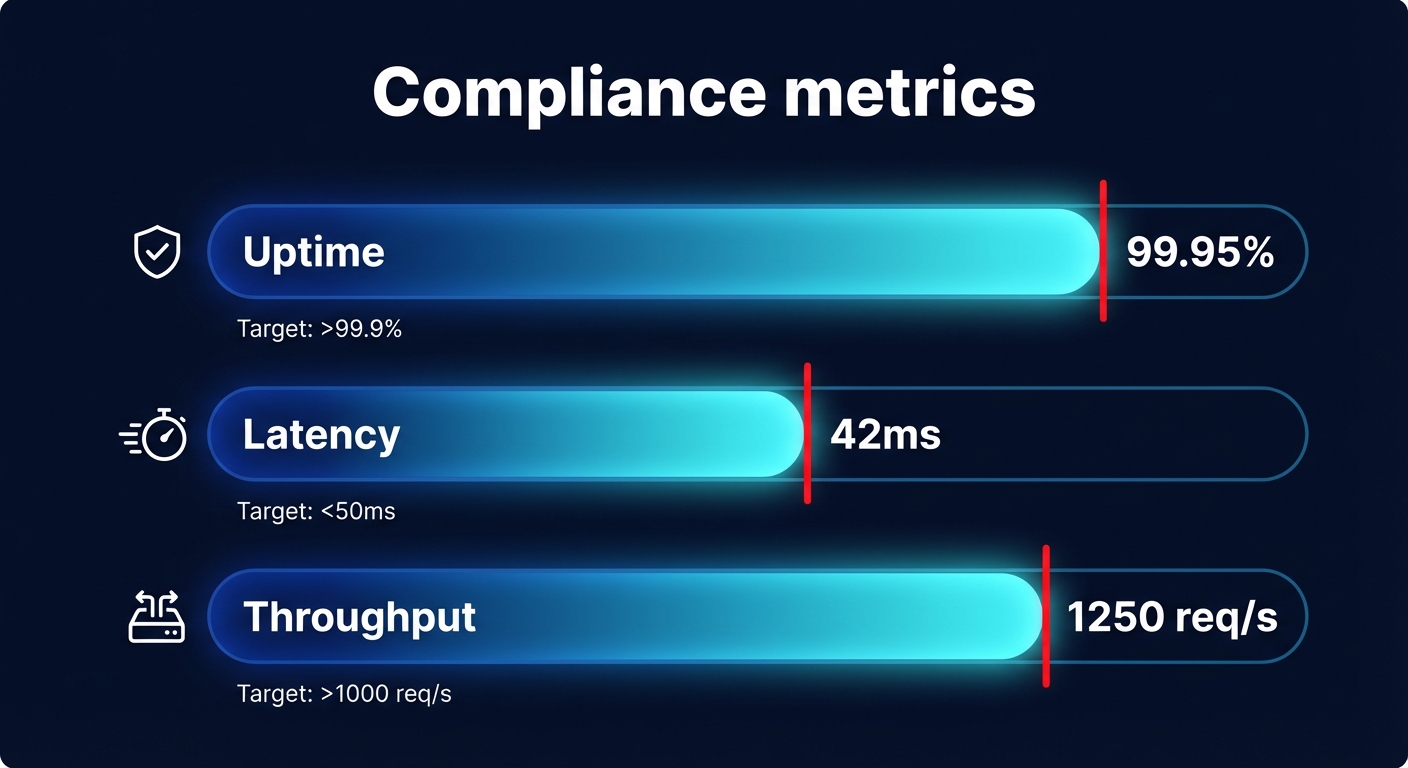
Uptime and availability targets
Uptime remains the most common metric for core infrastructure. For services like S3 or EC2, a 99.99% SLA allows for approximately 4.38 minutes of downtime per month. If your application logic requires “five nines” (99.999%) of availability, you cannot rely solely on the provider’s standard performance SLA. Instead, you must architect for higher resilience using multi-region failovers and global load balancing.
Storage and network latency
In storage-heavy or transactional workloads, Amazon EBS latency is often the real bottleneck. While AWS guarantees sub-millisecond latencies for premium volumes like io2, standard volumes like gp3 can experience fluctuations in “tail latency” that degrade the user experience. Continuous cloud performance benchmarking allows you to identify these patterns and decide when it is financially prudent to upgrade or right-size your storage volumes.
Data throughput capacity
AWS EBS throughput measures the volume of data transferred per second, which is distinct from IOPS. If your throughput drops below provisioned levels, your application may appear to be “up” in terms of connectivity, but it will be effectively unusable for data-intensive tasks. Monitoring these levels ensures that you are actually receiving the performance you are paying for in your monthly bill.
Navigating the fine print of risk and governance
Every AWS SLA includes a specific list of exclusions that engineering teams must understand. These agreements generally do not cover downtime caused by your own application code, security misconfigurations, or external factors like “Force Majeure” events. From a cloud cost governance perspective, relying on an SLA is a defensive strategy, but it is not a substitute for proactive system design.
Engineering leaders often use provider SLAs as a baseline to set their own internal Service Level Objectives (SLOs). This ensures that if a provider fails, the financial impact is partially offset by credits while the operational impact is mitigated by redundant architecture. Treating these agreements as a risk management tool – rather than a performance guarantee – allows you to balance reliability with cost efficiency more effectively.
Aligning SLA compliance with cost optimization
Understanding the nuances of performance guarantees is only half the battle. The other half is ensuring your infrastructure is optimized for both cost and performance so you aren’t overpaying for “gold-plated” SLAs that your specific workload doesn’t actually require.
Hykell helps you navigate this complex landscape by providing automated cloud cost optimization that respects your unique performance requirements. Instead of manually auditing bills for SLA breaches or hunting for over-provisioned resources, the Hykell observability platform provides real-time visibility into your Effective Savings Rate and actual resource utilization.
Whether you want to accelerate your Graviton gains for superior price-performance or you need precision-engineered rate optimization to reduce your compute spend by 40%, Hykell operates on autopilot. We only take a slice of what you save – if you don’t save, you don’t pay.
See how much you could be saving without compromising your performance guarantees. Calculate your potential AWS savings now.

