
Your database query just hung for 30 seconds. Again. You check CloudWatch and see your gp2 volume has burned through its burst credits—dropping from 3,000 IOPS to a sustained 300 IOPS. Meanwhile, your monthly EBS bill shows $12,000 in provisioned IOPS you’re barely using.
EBS performance hinges on two metrics most engineers treat as interchangeable: IOPS and throughput. Get the relationship wrong, and you’ll either overprovision expensive storage or watch your application crawl. This guide breaks down exactly how IOPS and throughput work together, the hard limits across every EBS volume type, how to monitor the right CloudWatch metrics, and how to configure storage that matches your workload without bleeding budget.
IOPS vs throughput: why you need to understand both
IOPS measures how many read or write operations your storage completes per second. A database executing 5,000 random 4 KB transactions? That’s 5,000 IOPS. Throughput measures the volume of data transferred per second, expressed in MB/s or MiB/s. Streaming a 50 MB video file? That’s throughput-bound work.
Most workloads need both, but the ratio determines your volume type. An OLTP database hammering your storage with tens of thousands of small, random writes is IOPS-constrained—you need low latency on every single operation. A log analytics pipeline reading multi-gigabyte files sequentially cares far more about throughput than operation count.
Here’s where it gets tricky: Amazon EBS offers SSD-backed volumes for transactional workloads (databases, virtual desktops, boot volumes) and HDD-backed volumes for throughput-intensive workloads (MapReduce, log processing). SSD volumes excel at random I/O. HDD volumes optimize for large sequential transfers. Match your workload to the wrong category and you’ll pay for performance you can’t use—or suffer latency your users will notice.
EBS volume types and their performance limits
AWS publishes maximum IOPS and throughput specs for each volume type, but the real-world limits depend on three factors: volume size, provisioned performance settings, and the EC2 instance you attach it to.
General Purpose SSD (gp3)
General Purpose SSD (gp3) provides 3,000 baseline IOPS and 125 MiB/s throughput regardless of volume size, with independent scaling of performance and capacity. You pay approximately $0.08/GB-month and can provision up to 16,000 IOPS and 1,000 MiB/s for additional cost.
The killer feature: gp3 decouples storage capacity from performance. A 100 GB gp3 volume delivers the same baseline 3,000 IOPS as a 10 TB volume. No burst credits, no performance cliffs. For most workloads, gp3 is the default choice—and as covered in our AWS EBS best practices documentation, migrating from gp2 to gp3 eliminates burst credit risk and saves approximately 20% per GiB.
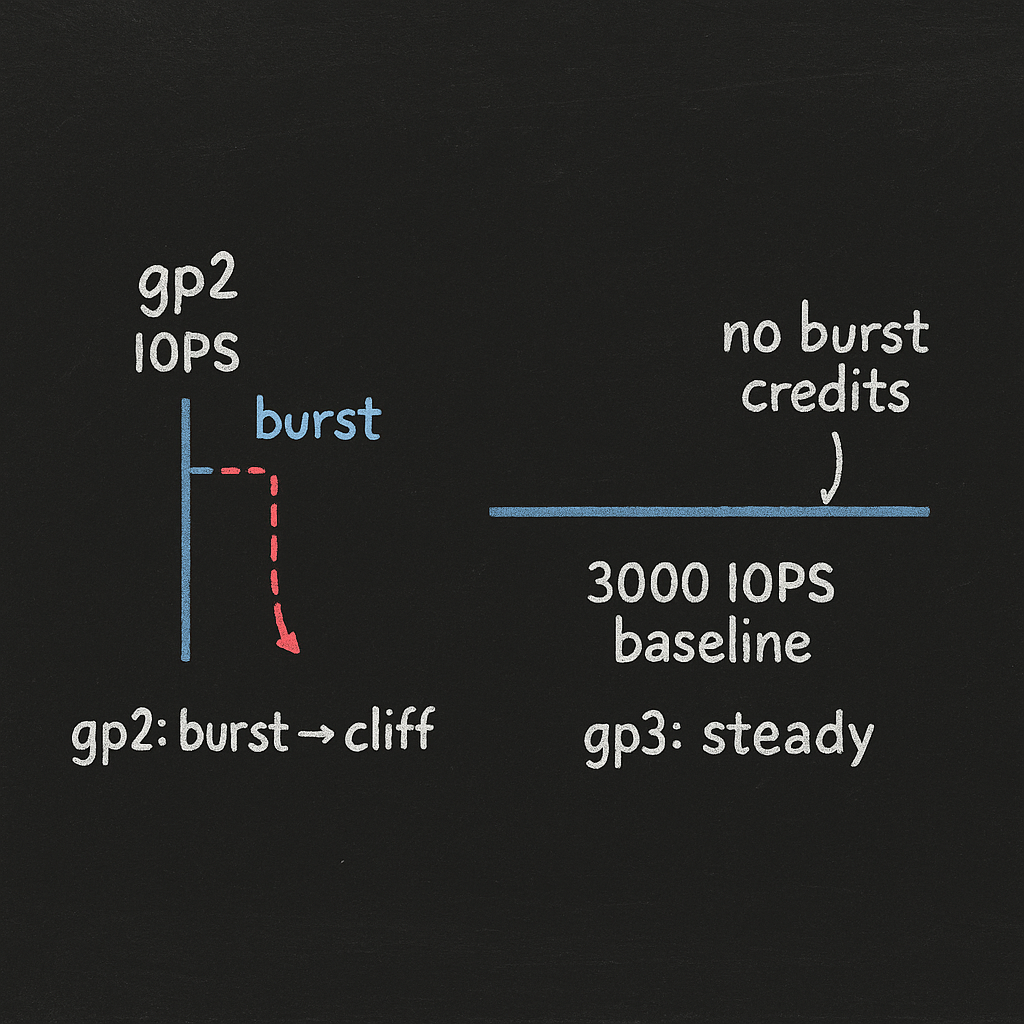
General Purpose SSD (gp2)
gp2 volumes provide performance that scales with capacity at 3 IOPS per GiB, with maximum 16,000 GiB size, 10,000 IOPS, and 160 MiB/s throughput. Smaller volumes can burst to 3,000 IOPS using I/O credits—but once those credits deplete, gp2 volumes under 1 TiB might burst to 3,000 IOPS but sustain only a few hundred IOPS once burst credits run dry.
A 500 GB gp2 volume sustains only 1,500 IOPS (500 × 3). When burst credits run out during peak traffic, your database queries stack up. The burst credit model makes gp2 unpredictable for production workloads, which is why gp3 storage is approximately 20% cheaper than gp2 while offering better performance for volumes under 1 TiB.
Provisioned IOPS SSD (io1 and io2)
io1 and io2 volumes support up to 64,000 IOPS and 1,000 MB/s throughput per volume for mission-critical applications with high performance demands. Provisioned IOPS SSD (io2) offers 99.999% durability compared to io1, making it ideal for critical database workloads requiring both high performance and reliability.
These volumes cost significantly more—io2 volumes cost $0.125/GB plus $0.065 per provisioned IOPS—but deliver consistent, single-digit millisecond latency. io2 and io2 Block Express support consistent, low-latency I/O up to 256,000 IOPS for the most demanding transactional workloads like SAP HANA or high-transaction-rate OLTP databases.
The catch: attaching a high-IOPS io2 volume to an undersized instance wastes money. Attaching a 64,000 IOPS io2 volume to a t3.large instance (which supports only 2,780 IOPS baseline) wastes money on unused capacity. You’re paying for 64,000 IOPS but the instance can’t deliver more than 2,780.
Throughput Optimized HDD (st1)
Throughput Optimized HDD (st1) is designed for large, sequential workloads like big data and data warehouses, with performance scaling by volume size measured in MB/s rather than IOPS. st1 volumes support up to 500 MiB/s throughput per volume but cannot be used as boot volumes, with pricing at approximately $0.045/GB-month.
st1 is designed for sequential workloads with up to 500 MiB/s throughput. Use st1 for ETL jobs, log processing, or data lake ingestion where you read or write large blocks sequentially. IOPS are capped at 500, so random access patterns will perform poorly.
Cold HDD (sc1)
Cold HDD (sc1) provides the lowest cost per GB among EBS volume types at $0.025/GB-month but has the lowest performance with a maximum 250 MiB/s throughput, suitable for infrequently accessed data. sc1 is the lowest cost option for infrequently accessed data.
Use sc1 for cold archives, backup targets, or compliance data you rarely touch. Like st1, sc1 volumes cannot be used as boot volumes.
Instance-level throughput limits: the hidden bottleneck
Provisioning a high-performance EBS volume means nothing if your EC2 instance can’t push data through the pipe. EBS performance scales with instance size, with larger instances providing up to 40 Gbps dedicated EBS bandwidth.
t3.medium instances deliver only 347 Mbps baseline EBS bandwidth despite 2,085 Mbps burst capability. If you attach a gp3 volume configured for 1,000 MiB/s (8,000 Mbps) to a t3.medium, you’ll never see more than 347 Mbps sustained throughput. The instance is the choke point.

In contrast, m7i.large or c7i.large instances provide 10 Gbps dedicated EBS bandwidth for high-throughput workloads. Always check the instance type’s “EBS-optimized” bandwidth before provisioning IOPS or throughput. AWS publishes these specs on every instance type detail page.
For more on matching instance types to workload requirements, see our EC2 instance type selection guide.
Monitoring EBS performance with CloudWatch
You can’t optimize what you don’t measure. AWS CloudWatch exposes several EBS metrics that tell you whether you’re hitting volume or instance limits.
Key CloudWatch metrics for EBS
VolumeReadOps / VolumeWriteOps count the total number of read or write operations over the period. Divide by the period length in seconds to calculate actual IOPS. If you see sustained IOPS near your volume’s limit, you’re bottlenecked.
VolumeReadBytes / VolumeWriteBytes track total bytes transferred. Divide by the period to get throughput in bytes per second. Compare this to your volume’s throughput limit—125 MiB/s for baseline gp3, 1,000 MiB/s for max gp3, and so on.
VolumeThroughputPercentage shows the percentage of provisioned throughput delivered. VolumeThroughputPercentage near 100% indicates saturation of the volume’s throughput capacity. If this metric stays at 100% during peak load, you need more throughput—either by increasing provisioned throughput for gp3, io1, or io2, or switching to a higher-throughput volume type.
VolumeQueueLength measures the number of I/O operations waiting in the queue. VolumeQueueLength consistently above 10 for gp3 or io2 volumes indicates an I/O bottleneck. For databases and latency-sensitive applications, VolumeQueueLength should hover near 1 during normal load. A queue depth above 10 means I/O requests are piling up faster than the volume can service them.
BurstBalance (gp2, st1, sc1 only) tracks remaining burst credits for gp2, st1, and sc1 volume types. When BurstBalance hits zero on a gp2 volume, performance drops to the baseline rate of 3 IOPS per GiB. A sustained zero balance during business hours is a red flag.
For a deeper dive into setting up CloudWatch across your AWS environment, see our guide on AWS CloudWatch application monitoring.
Setting alarms to catch performance issues
Configure CloudWatch alarms on VolumeThroughputPercentage and VolumeQueueLength. Set a threshold—VolumeThroughputPercentage greater than 80% for 5 minutes, or VolumeQueueLength greater than 10 for 10 minutes. When the alarm triggers, you know you need to scale performance or re-architect your storage.
Alarm on BurstBalance for any gp2 volumes still in production. If BurstBalance drops below 20%, you’re about to hit a performance cliff. That’s your cue to migrate to gp3.
For guidance on monitoring beyond EBS, see our AWS KPIs guide to tie storage performance back to business outcomes.
How to choose the right EBS volume type for your workload
Start by profiling your I/O pattern. Is your application doing lots of small, random reads and writes? Or large sequential transfers? What’s the actual IOPS and throughput demand?
Transactional workloads (databases, application servers)
If you’re running MySQL, PostgreSQL, MongoDB, or any OLTP database, you care about IOPS and latency. Start with gp3. gp3 provides baseline 3,000 IOPS and 125 MiB/s regardless of volume size with no burst credits. If monitoring shows sustained demand above 3,000 IOPS, provision additional IOPS on the gp3 volume up to 16,000 IOPS.
For mission-critical production databases where every millisecond matters and you need five-nines durability, upgrade to io2. gp3 targets single-digit millisecond latency for typical workloads, but io2 delivers sub-millisecond latency at high IOPS with better durability guarantees.
Throughput-intensive workloads (ETL, log processing, data lakes)
For workloads reading or writing large files sequentially—ETL pipelines, Hadoop or Spark clusters, log aggregation—throughput is king. Use st1. It’s optimized for sequential access and costs significantly less than SSD volumes. You can achieve 500 MiB/s throughput on an st1 volume at a fraction of the cost of provisioning a high-throughput gp3 or io2 volume.
Boot volumes and low-demand workloads
EC2 boot volumes rarely need high IOPS. A gp3 volume at baseline—3,000 IOPS and 125 MiB/s—is overkill for most boot disks. But since you can’t use HDD volumes for boot, gp3 remains the cost-effective default. Avoid provisioning extra IOPS unless you have a specific reason.
Archive and infrequent access
For backups, compliance archives, or data you touch once a month, use sc1. At $0.025/GB-month, it’s the cheapest EBS option. Performance is limited with a maximum 250 MiB/s, but that’s fine if you’re storing data “just in case.”
For more strategies on balancing cost and performance across your entire EBS footprint, see our resources on EBS cost optimization best practices and AWS EBS performance optimization.
Configuring gp3 volumes: decoupling size from performance
One of gp3’s biggest advantages is that you can scale IOPS and throughput independently of storage size. A 100 GB gp3 volume can deliver 16,000 IOPS and 1,000 MiB/s—the same as a 10 TB volume—if you’re willing to pay for the provisioned performance.
Baseline gp3 gives you 3,000 IOPS and 125 MiB/s included in the $0.08/GB-month price. Additional IOPS cost $0.005 per provisioned IOPS-month. Additional throughput above 125 MiB/s costs $0.04 per MiB/s-month.
Example: You need 8,000 IOPS and 500 MiB/s for a 500 GB database volume.
- Storage: 500 GB × $0.08 = $40/month
- Additional IOPS: (8,000 – 3,000) × $0.005 = $25/month
- Additional throughput: (500 – 125) MiB/s × $0.04 = $15/month
- Total: $80/month
Compare that to io2: 500 GB × $0.125 = $62.50, plus 8,000 IOPS × $0.065 = $520, for a total of $582.50/month. The gp3 volume costs 86% less.
gp3 offers 3,000 baseline IOPS versus gp2’s burst-based performance model and gp3 volumes cost $0.08/GB compared to gp2’s $0.10/GB—a 20% lower base cost. Unless you have a specific reason to stick with gp2 like legacy automation, migrate to gp3.
For a complete comparison of EBS volume types and their performance characteristics, see our AWS IOPS explained documentation.
Common mistakes that cost you money
Overprovisioning IOPS you never use
AWS Compute Optimizer identifies 20-30% of volumes as candidates for optimization. Many teams provision 10,000 or 16,000 IOPS “just in case,” then never see peak demand exceed 2,000 IOPS. Check your CloudWatch metrics over the past two weeks. If your 95th percentile IOPS is well below your provisioned limit, scale down.
Ignoring instance-level bandwidth limits
You provision a high-performance volume but attach it to a burstable instance like a t3 or t2. The instance can’t deliver the bandwidth, so you never see the performance you’re paying for. Always verify the instance type supports the EBS throughput your volume can deliver.
Leaving gp2 volumes in production
gp2 volumes under 1 TiB might burst to 3,000 IOPS but sustain only a few hundred IOPS once burst credits deplete. If you have gp2 volumes still running in production, especially small ones, migrate them to gp3. You’ll get predictable performance and a 20% cost reduction.
Mismatched workload and volume type
Running a sequential analytics job on an expensive io2 volume, or a transactional database on an st1 volume. Both scenarios waste money or cripple performance. Match your I/O pattern to the volume type.
How Hykell automates EBS optimization
Manually auditing hundreds of EBS volumes, cross-referencing CloudWatch metrics, and deciding which to resize or migrate is tedious engineering work. Hykell’s automated platform continuously monitors your actual IOPS and throughput usage, identifies underutilized volumes, and recommends migrations—like gp2 to gp3—that reduce cost without impacting performance.
Hykell’s cost audits typically uncover 20–30% of EBS spending tied to overprovisioned IOPS, orphaned snapshots, or volumes attached to stopped instances. The platform automatically flags these, calculates potential savings, and can execute optimizations on autopilot. You only pay a percentage of what you save—if Hykell doesn’t reduce your bill, you don’t pay.
For example, one Hykell customer was running 200+ gp2 volumes averaging 60% burst credit depletion during peak hours. Hykell migrated them to gp3, eliminated the burst credit risk, and cut EBS costs by 22%—freeing up $18,000/month that the engineering team reinvested in scaling the application tier.
For broader AWS cost strategies, see our AWS cost management best practices.
Start optimizing your EBS performance and cost today
EBS throughput and IOPS are two sides of the same coin. Ignore either one, and you’ll either pay for performance you can’t use or suffer latency that hurts your users. The right approach: profile your workload, choose the volume type that matches your I/O pattern, monitor CloudWatch metrics, and continuously optimize based on actual demand.
Most teams spend hours each month auditing EBS volumes, checking CloudWatch dashboards, and calculating whether a migration or resize makes sense. Hykell automates that entire process, finding savings opportunities you’d never spot manually and executing optimizations without risking performance.
Ready to see how much you can save? Use Hykell’s cost savings calculator to get an instant estimate, or learn how Hykell works to uncover hidden waste across your entire AWS environment—EBS, EC2, snapshots, and beyond.

