Most engineering leaders assume Spot Instances are too risky for anything resembling production workloads. Yet Netflix, NFL, and countless other organizations run business-critical systems on Spot capacity, achieving up to 90% savings without compromising stability. The difference? Intelligent automation that treats interruptions as routine events rather than catastrophic failures.
When AWS reclaims Spot capacity—typically with just two minutes’ notice—poorly configured workloads fail spectacularly. But with proper automation strategies around diversification, capacity rebalancing, and interruption handling, your Spot-based infrastructure can match or exceed the reliability of On-Demand instances at a fraction of the cost.
Understanding when Spot Instances make sense for stable workloads
Not every workload belongs on Spot capacity, but the category extends far beyond obvious batch jobs. Your workload is likely a good candidate if it meets these criteria.
The application must be fault-tolerant by design, capable of gracefully handling instance terminations without data loss or customer impact. This includes containerized microservices with health checks, distributed data processing frameworks like Spark or Hadoop, and any stateless application where work can migrate between instances. Stateful workloads or critical APIs serving real-time traffic remain poor fits without additional architectural changes.
Flexible execution windows matter tremendously. Jobs that can pause and resume or be redistributed across other instances handle interruptions seamlessly. Machine learning training runs with regular checkpointing, CI/CD pipelines that retry failed builds, and analytics queries that can restart from the last committed state all thrive on Spot capacity. The ability to defer or reschedule work transforms what could be a service disruption into a transparent capacity shift.
Horizontal scalability provides the architectural foundation for Spot reliability. Systems that spread load across multiple instances naturally survive individual node failures. When one Spot Instance terminates, the remaining nodes absorb its workload until replacement capacity launches. This pattern turns Spot interruptions into non-events that your users never notice.
The NFL provides a compelling production example: they use 4,000 EC2 Spot Instances across 20+ instance types to build their season schedule, saving $2 million annually. Their computational workload divides into small segments that automatically redistribute when capacity shifts, demonstrating how proper architecture enables production stability on Spot. Rather than treating Spot as a discount option for non-critical work, they engineered their core scheduling system to embrace capacity volatility.
The three pillars of Spot automation
Achieving production-grade reliability on Spot Instances requires automation across three critical areas. Manual management fails at scale because interruptions occur randomly and frequently across large fleets. The engineering effort required to manually respond to each interruption quickly exceeds any cost savings. Instead, you need systematic automation that makes optimal decisions faster than humans can react.
Instance type diversification across capacity pools
AWS groups unused EC2 capacity into Spot capacity pools defined by instance type and Availability Zone. Requesting a single instance type from one pool creates fragility—when that specific capacity depletes, you face interruptions. The solution is aggressive diversification across multiple capacity pools, giving your workloads numerous options when capacity shifts.
AWS recommends flexibility across at least 10 instance types for each workload. Think broadly about instance compatibility: if your application runs well on c5.12xlarge instances, it likely performs similarly on c5.24xlarge, c5n.18xlarge, c6i.12xlarge, and m5.12xlarge. Each additional compatible instance type represents another capacity pool your automation can tap. Don’t artificially constrain yourself to a single instance family when your workload can run effectively across multiple families with similar compute profiles.
Consider alternatives that scale vertically within a family as well. If you need 12 vCPUs and 48GB of memory, both c5.3xlarge (12 vCPU, 24GB) with memory-optimized flags and m5.3xlarge (12 vCPU, 48GB) might serve your needs. Expanding your instance type flexibility exponentially increases available capacity pools, dramatically reducing interruption probability.
Modern AWS features simplify this diversification. Attribute-based instance selection lets you specify requirements like “16 vCPUs, 64GB RAM, Intel or AMD processor” rather than listing specific types. Your Auto Scaling group or ECS cluster then automatically selects from any instance matching those attributes, instantly expanding your capacity pool options without manually maintaining long lists of instance types.
When configuring EC2 Auto Scaling groups, EC2 Fleet, or AWS Batch, use the `SPOTCAPACITYOPTIMIZED` allocation strategy. This instructs AWS to launch instances from the capacity pools with the deepest available capacity—the pools least likely to face interruptions in the near term. The automation continuously evaluates capacity depth and shifts new launches accordingly, optimizing for both cost and stability rather than cost alone.
Proactive capacity rebalancing
Waiting for interruption notices before replacing instances creates unnecessary risk and service degradation. Capacity rebalancing triggers replacement instance launches before existing instances receive termination notices, based on AWS’s internal capacity forecasting. This proactive stance maintains aggregate capacity and service quality throughout capacity transitions.
Enable capacity rebalancing in your Auto Scaling groups to receive early warning signals when Spot capacity becomes constrained. AWS monitors real-time capacity trends across its infrastructure and emits rebalance recommendations when it detects that your instances face elevated interruption risk. Your automation responds by launching replacement instances in healthier capacity pools while the at-risk instances continue running, ensuring you never lose capacity during the transition.
This proactive approach delivers two critical advantages. First, new instances complete their boot sequence and health checks before old instances terminate, maintaining aggregate capacity throughout the transition. You avoid the capacity dip that occurs when instances terminate before replacements become available. Second, workloads can gracefully drain from at-risk instances rather than handling abrupt terminations, reducing the blast radius of interruptions and improving customer experience.
The NFL scheduling workload relies heavily on this pattern. Their system continuously monitors capacity signals and preemptively migrates work between instances as capacity conditions shift, maintaining computational throughput even as individual instances come and go. The result is stable performance metrics despite running entirely on interruptible capacity.
Automated interruption handling
Despite diversification and rebalancing, some interruptions remain inevitable. Robust Spot automation must detect termination notices and respond appropriately within the available warning window. The two-minute notification window sounds generous until you consider everything that must happen: detecting the notice, gracefully stopping work, draining connections, deregistering from load balancers, and potentially checkpointing state.
AWS publishes interruption notices through EC2 instance metadata and EventBridge, giving you two minutes to prepare. Your automation should monitor these signals and trigger immediate response workflows that execute in parallel rather than sequentially to maximize available time.
For containerized workloads on ECS or EKS, configure your orchestrator to receive interruption notices via daemonsets or container agents. When a node faces termination, the orchestrator immediately marks it as unschedulable, drains existing pods or tasks to healthy nodes, and updates load balancer targets. Most well-configured container platforms complete this process in under 90 seconds, leaving a comfortable buffer before termination. The key is testing these workflows under realistic load—many teams discover their graceful shutdown procedures take longer than expected when handling dozens of concurrent connections.
For batch processing workloads, implement checkpointing at intervals less than the interruption window. Dividing jobs into segments of 30 minutes or less significantly reduces interruption impact—even if AWS reclaims capacity mid-job, you’ve only lost 30 minutes of progress. AWS Batch natively handles this pattern, automatically requeueing interrupted jobs and resuming from the last successful checkpoint without manual intervention.
For traditional instance-based applications, run monitoring scripts that poll the instance metadata endpoint at 5-second intervals. Upon detecting an interruption notice, these scripts trigger graceful shutdown procedures: deregister from load balancers, flush local caches to persistent storage, and signal cluster managers to redistribute work. The script should execute these steps in parallel where possible and include timeout logic to force termination if graceful shutdown exceeds 110 seconds.
Native AWS automation versus third-party tooling
AWS provides robust native features for Spot automation, but third-party platforms add abstraction layers that simplify multi-workload management. The right choice depends on your organization’s scale, technical sophistication, and architectural complexity.
Native AWS capabilities
Auto Scaling groups handle the core automation for EC2-based workloads. Configure mixed instance types, enable capacity rebalancing, and set capacity-optimized allocation strategies—all through CloudFormation or Terraform templates. The tight integration with other AWS services like Application Load Balancers, CloudWatch, and EventBridge provides low-latency responses to capacity changes. For teams already invested in infrastructure-as-code practices, native Auto Scaling groups offer the most transparent and controllable automation with no additional vendor dependencies.
EC2 Fleet and Spot Fleet offer more granular control over instance diversity and capacity allocation. Use these when you need precise control over instance type weighting or complex allocation strategies across multiple Spot capacity pools. These features excel in scenarios requiring custom capacity distribution logic that Auto Scaling groups don’t support out of the box.
EKS with Karpenter or Cluster Autoscaler automates Spot management for Kubernetes workloads. Karpenter, AWS’s newer node provisioning tool, evaluates Spot capacity in real-time and automatically diversifies node types based on pod requirements and capacity availability. It handles interruption notices, cordons affected nodes, and launches replacements—all without manual intervention. For organizations running containerized workloads on Kubernetes, Karpenter represents the most sophisticated native option, though it requires understanding Kubernetes-specific concepts like node selectors and pod topology spread constraints.
ECS with Spot capacity providers abstracts Spot management for container workloads outside Kubernetes. Define capacity provider strategies that specify target Spot percentages, and ECS automatically distributes tasks across Spot and On-Demand capacity based on availability. This approach works well for teams preferring ECS’s simpler operational model over Kubernetes complexity while still wanting automated Spot management.
When third-party platforms add value
Platforms like Spot.io (acquired by NetApp), Cast.ai, and others layer additional intelligence on top of native AWS features. These tools can accelerate adoption and reduce operational complexity, but they introduce vendor dependencies and additional costs that must be weighed against their benefits.
Cross-cloud abstraction matters if your organization runs workloads across AWS, Azure, and GCP. Third-party platforms provide unified Spot management APIs and policies rather than learning three different toolsets. Teams managing multi-cloud deployments often find this consistency valuable enough to justify the additional abstraction layer.
ML-driven capacity prediction is where some third-party platforms claim differentiation. They analyze historical interruption patterns and market pricing trends to predict optimal instance types and capacity pools beyond AWS’s native allocation strategies. However, AWS’s own `SPOTCAPACITYOPTIMIZED` strategy incorporates similar signals, and the practical reliability difference often proves marginal in real-world testing.
Advanced workload migration capabilities can help convert traditionally stateful workloads to Spot-friendly architectures by implementing custom checkpointing, state replication, or fast failover mechanisms. This is valuable if you’re migrating legacy applications not originally designed for cloud-native patterns, though it comes with the risk of vendor lock-in to proprietary frameworks.
Simplified policy management lets you define high-level policies—”keep costs under $X while maintaining 99.9% availability”—and have the platform manage the implementation details. This abstraction can reduce operational burden for teams lacking deep AWS expertise, though it also obscures the underlying mechanisms and makes troubleshooting more difficult.
For most AWS-focused engineering teams, native features provide sufficient automation capabilities, especially when combined with infrastructure-as-code practices that codify your Spot strategies. The transparency, control, and zero vendor lock-in often outweigh the convenience benefits of third-party platforms. Reserve third-party tools for scenarios where they solve specific problems that native features cannot address.
Architecting workloads for Spot stability
Automation only succeeds when your application architecture treats instance failures as routine events rather than exceptional circumstances requiring human intervention. These patterns transform interruptions from incidents into background noise that your monitoring systems track but your operations team rarely notices.
Implement meaningful health checks
Configure aggressive health checks in your load balancers and orchestrators that detect degraded instances quickly. When an instance receives an interruption notice and begins draining, health checks should fail immediately, triggering automatic removal from load balancer target groups. This prevents new requests from routing to doomed instances while allowing in-flight requests to complete gracefully.
For ECS and EKS, configure both liveness and readiness probes with appropriate thresholds. The liveness probe determines if the container should be restarted, while the readiness probe controls whether it receives traffic. Your interruption handler script should immediately update readiness status to signal that the container should stop receiving traffic while allowing sufficient time for existing requests to complete processing.
Health check timing requires careful tuning. Set intervals frequent enough to detect failures quickly—typically 5-10 seconds—but with timeout and threshold values that avoid false positives during legitimate traffic spikes. Many teams discover through production incidents that their health checks were too lenient, allowing degraded instances to remain in rotation longer than optimal.
Checkpoint long-running work
Any job requiring more than 30 minutes should implement intermediate checkpoints that save progress to durable storage. Save progress to S3, DynamoDB, or RDS at regular intervals so interrupted jobs resume from the most recent checkpoint rather than restarting from scratch. The checkpoint frequency should balance the overhead of saving state against the cost of lost work—typically every 10-30 minutes depending on computational intensity.
AWS Batch automatically handles checkpointing for array jobs and multi-node parallel jobs through its built-in retry and resumption logic. For custom batch processing, implement your own checkpoint logic that writes state every 15-30 minutes. Avoid running jobs longer than one hour on Spot without checkpoints—the interruption probability increases with runtime, and losing an hour of computational work becomes increasingly expensive.
The checkpoint format matters as much as frequency. Design your checkpoint data to be self-describing and versioned, allowing your application to validate checkpoint integrity and handle schema evolution. Many teams implement checksums or cryptographic hashes to detect corrupted checkpoints, falling back to earlier valid checkpoints rather than failing the entire job.
Design for horizontal scalability
Deploy more smaller instances rather than fewer large instances to minimize the impact of individual interruptions. A workload running across 50 c5.2xlarge instances tolerates interruptions better than the same workload on 5 c5.18xlarge instances. When an interruption occurs in the first scenario, you lose 2% of capacity; in the second, you lose 20%—a difference your customers may notice.
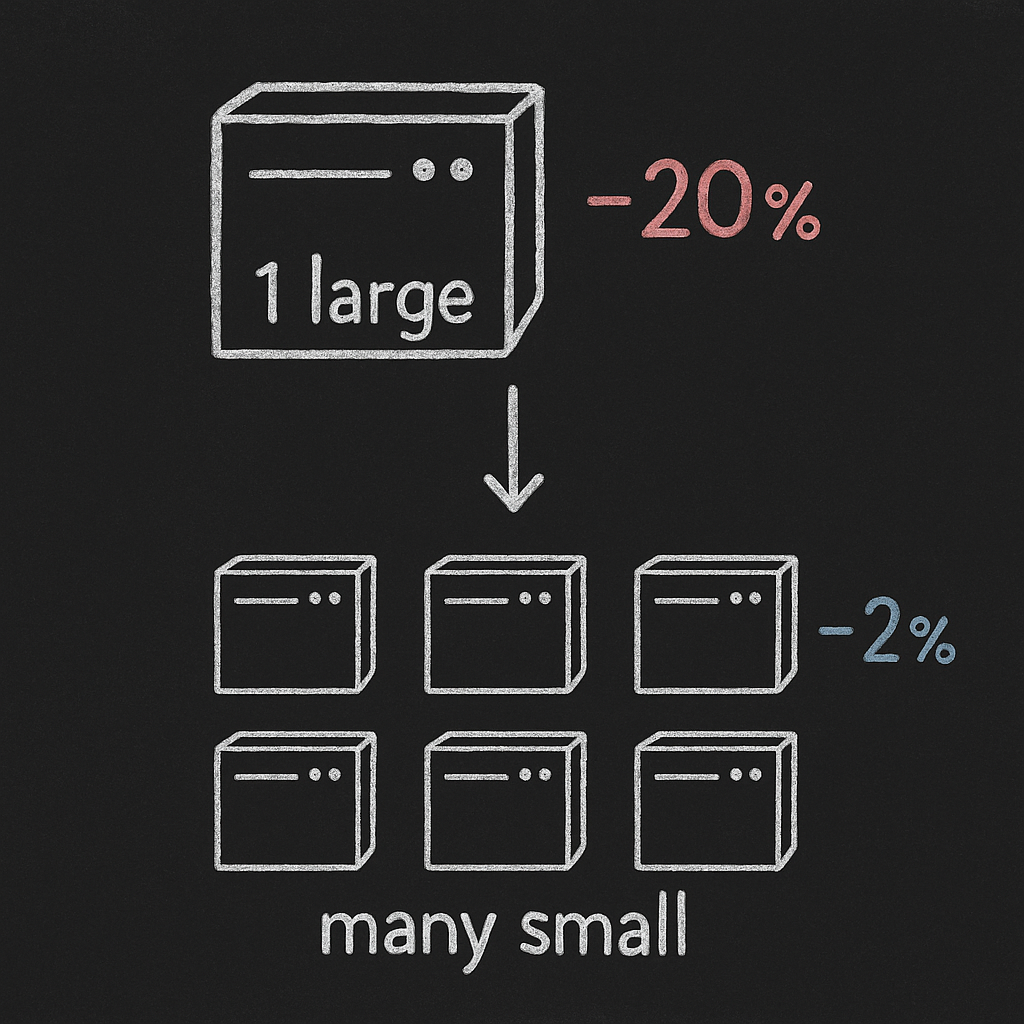
This granularity also improves Auto Scaling responsiveness and cost efficiency. Adding or removing individual instances provides fine-grained capacity adjustments rather than large step changes that can cause oscillation between over-provisioned and under-provisioned states. Your system can more precisely match capacity to actual demand, reducing waste.
The performance implications of horizontal scaling deserve consideration. Smaller instances sometimes introduce network or coordination overhead that larger instances avoid. Profile your specific workload to find the optimal balance—usually somewhere between extreme fragmentation (100 tiny instances) and dangerous concentration (5 massive instances).
Separate stateful components
Keep persistent state in managed services like RDS, ElastiCache, DynamoDB, or EFS rather than on EC2 instance storage. Your Spot Instances should be cattle, not pets—completely disposable and interchangeable without requiring special handling or data recovery procedures.
For applications requiring local state, like Kafka brokers or Elasticsearch nodes, run these components on Reserved or On-Demand instances to provide stability, while using Spot for stateless components like API gateways, web servers, or data processing workers. This hybrid approach delivers most of Spot’s cost benefits while maintaining reliability for your stateful tier.
When separation isn’t architecturally feasible, implement aggressive replication and fast failover mechanisms. Kafka running on Spot instances, for example, requires replication factor of at least 3 and clients configured to handle broker failures gracefully. The additional replication overhead and complexity must be weighed against the cost savings—sometimes paying On-Demand prices for simplicity makes more economic sense than engineering complex failover systems.
Monitoring and optimizing your Spot fleet
Effective Spot automation requires continuous monitoring to identify patterns, detect emerging issues, and optimize configurations. Treat your Spot implementation as a living system that needs ongoing observation and adjustment rather than a one-time configuration.
Track interruption rates and patterns
Use the Spot Interruption Dashboard to monitor which instance types and Availability Zones experience frequent reclamations. If you notice specific combinations facing repeated interruptions, remove them from your instance type configurations and expand diversification into more stable capacity pools. Interruption patterns change over time as AWS capacity shifts, so this isn’t a set-and-forget exercise.
Interruption rates vary significantly by Region, Availability Zone, and instance type. Some capacity pools maintain extremely low interruption rates for months, while others experience daily capacity volatility driven by customer demand patterns in that geography. Your automation should learn these patterns and favor stable pools, though over-optimization for current conditions can leave you vulnerable when patterns shift.
Create CloudWatch dashboards that track interruption frequency, replacement latency, and capacity rebalance events. Correlate these metrics with application performance indicators to understand how Spot volatility impacts your actual service quality. Many teams discover that interruption rates appearing concerning in isolation have no measurable customer impact, allowing them to confidently increase Spot usage.
Analyze cost versus stability tradeoffs
Monitor your actual realized savings versus interruption frequency to ensure you’re achieving the intended cost reduction. While Spot can deliver up to 90% savings over On-Demand pricing, aggressive automation optimizing purely for cost sometimes selects unstable capacity pools that cause operational issues exceeding the cost benefits.
Set CloudWatch alarms for interruption rates exceeding acceptable thresholds. If your interruption rate climbs above 5-10% weekly, your diversification strategy needs adjustment or you’ve pushed too much capacity into Spot pools. The optimal threshold depends on your specific workload characteristics—batch processing tolerates higher interruption rates than customer-facing services.
Consider the full cost equation beyond EC2 pricing. Include engineering time spent on automation maintenance, the cost of overprovisioning to handle interruptions, and potential revenue impact from degraded performance. Some workloads achieve better total cost of ownership running 70% on-demand with careful rightsizing than running 90% on Spot with excessive overhead.
Calculate effective savings
Track your total EC2 spend including both Spot savings and On-Demand fallback costs to understand real financial impact. Some workloads achieve 70-80% Spot coverage with minimal interruption impact, while others stabilize at 40-50% Spot. Combining Reserved Instances for baseline capacity with Spot for burst capacity often delivers the optimal balance, reducing overall compute costs by 60-90% compared to pure On-Demand pricing.
Break down savings by workload type and instance family to identify where Spot delivers maximum value. Your data pipeline running overnight might achieve 95% Spot coverage while your web tier maintains 60% Spot, and that variation is fine—optimize each workload independently rather than forcing a single strategy across your entire infrastructure.
Factor in operational overhead when calculating ROI. If your team spends significant engineering time managing Spot interruptions, responding to capacity-related incidents, or tuning automation, those labor costs erode savings. Mature automation should require minimal ongoing management—a sign you’ve properly architected the system. When operational burden exceeds savings, you’ve over-optimized for cost at the expense of efficiency.
Getting started with production Spot workloads
Start small and expand gradually rather than attempting a wholesale migration that creates risk and complexity. Identify one non-critical production workload with natural fault tolerance—perhaps a background job processor, data pipeline, or development environment—and migrate it to Spot using systematic steps that build confidence.
First, analyze the workload’s compute requirements. Document the instance types currently used, CPU and memory utilization patterns, performance requirements, and latency sensitivity. This baseline helps you identify compatible instance types for diversification and set appropriate performance expectations. Understanding normal performance variation makes it easier to detect when Spot interruptions cause actual degradation versus typical fluctuation.
Second, architect for failure by adding health checks, implementing checkpointing if needed, and verifying your application handles instance failures gracefully. Test by randomly terminating instances in staging environments—tools like Netflix’s Chaos Monkey excel at validating failure handling. Many teams discover architectural gaps during this testing that would have caused production incidents if not addressed proactively.
Third, configure your Auto Scaling group or ECS cluster with mixed instance types and capacity-optimized allocation. Start conservative—perhaps 30% Spot, 70% On-Demand—to validate your automation before increasing Spot percentage. This gradual approach lets you build operational confidence and catch configuration issues before they impact significant capacity.
Fourth, enable capacity rebalancing and implement interruption handling logic. Monitor closely during the first few weeks, examining how your system responds to actual interruptions. Real-world interruption patterns often differ from theoretical expectations, and this observation period helps you tune thresholds and procedures.
Finally, iterate based on observed behavior. Expand instance type diversity if you see frequent interruptions in specific capacity pools. Increase Spot percentage as confidence grows in your automation’s reliability. Many organizations achieve 30-40% cost reduction through comprehensive optimization efforts that include Spot, rightsizing, and commitment purchases working together.
Most organizations following this pattern achieve stable production workloads running 60-80% on Spot capacity within 3-6 months, with interruption handling so seamless that engineering teams stop tracking individual interruptions. The key is treating it as a journey rather than a destination—continuously refining your approach based on operational learnings.
Achieving production reliability with Spot automation
The engineering leaders who successfully run production workloads on Spot share a common philosophy: they design systems that treat interruptions as expected events rather than exceptional failures. Combined with automation that continuously optimizes instance selection and proactively rebalances capacity, this approach transforms Spot from a risky experiment into a reliable cost optimization strategy delivering massive savings.
Your specific implementation will vary based on workload characteristics, risk tolerance, and existing architecture. Some teams achieve comprehensive optimization across compute, storage, and commitment strategies. Others focus narrowly on Spot for specific workload types while maintaining traditional instances elsewhere. Both approaches succeed when they match automation sophistication to workload requirements rather than forcing inappropriate strategies.
The key is starting with proper automation foundations. Manual Spot management doesn’t scale and creates operational burden that often exceeds cost savings. Whether you build on native AWS features or adopt third-party platforms, ensure your automation handles the three critical pillars: diversification across capacity pools, proactive rebalancing before interruptions, and graceful interruption handling within the two-minute window.
If you’re spending significant engineering effort managing Spot capacity or want to optimize your entire AWS infrastructure on autopilot, Hykell automates these complex decisions across your compute fleet. We handle instance selection, commitment optimization, and capacity management so your team focuses on building products rather than managing infrastructure. Discover how much you could save with automated optimization that maintains performance while reducing AWS costs by up to 40%.