Did you know that 40% of EC2 instances run below 10% CPU utilization even during peak hours? You are likely paying for “ghost” capacity that never serves a single request, turning your AWS environment into an expensive, underutilized asset.
Balancing performance, reliability, and cost is the primary challenge for modern FinOps and engineering leaders. To solve this, you need to move beyond simple visibility and toward a structured approach to resource allocation. By optimizing how you provision compute, storage, and networking, you can reclaim significant portions of your budget without compromising application stability.
Compute allocation: Right-sizing the engine
Compute is often the largest line item on an AWS bill, yet it is frequently the most mismanaged. Effective cloud resource right-sizing begins with matching instance types and sizes to your actual workload requirements. Many teams default to general-purpose M-family instances, but this often leads to over-provisioning memory or CPU. For example, migrating a memory-intensive workload from a t3.xlarge to an r6g.large can yield potential savings of 40% while better aligning with actual demand.
Strategic instance selection and generation upgrades
Your EC2 instance type selection should always prioritize the latest hardware generations to maximize price-performance. AWS typically releases new generations every 18 to 24 months, offering 15% to 25% better performance per vCPU. Migrating to AWS Graviton instances can cut compute costs by up to 40% while improving throughput and lowering your carbon footprint. For instance, moving from m6i to m7g instances typically delivers a 25% to 35% cost reduction for containerized workloads.
Leveraging elastic scaling and commitment models
To maintain reliability while cutting costs, you must implement automatic cloud resource scaling. By using target tracking policies that maintain average CPU utilization at 50% to 70%, you ensure that capacity expands only when necessary. You should also consider the following strategies:
- Establish a “floor” of reserved capacity using Savings Plans to cover your baseline workloads.
- Utilize AWS EC2 auto-scaling best practices by incorporating Spot Instances for fault-tolerant or non-production tiers, which can offer up to 90% savings compared to on-demand pricing.
- Implement predictive scaling to forecast traffic and raise minimum capacity ahead of time, preventing latency during sudden spikes.
Storage allocation: Eliminating the convenience tax
Storage costs often spiral due to “orphaned” resources and outdated volume types. Internal research indicates that mid-sized companies frequently discover over 15TB of unattached EBS volumes, representing pure waste that generates monthly charges without providing value. A primary pillar of EBS cost optimization is the migration from gp2 to gp3 volumes. This transition typically reduces storage costs by 20% and allows you to decouple IOPS and throughput from volume size. This means you no longer have to provision an oversized 1TB volume just to get the IOPS your database requires.
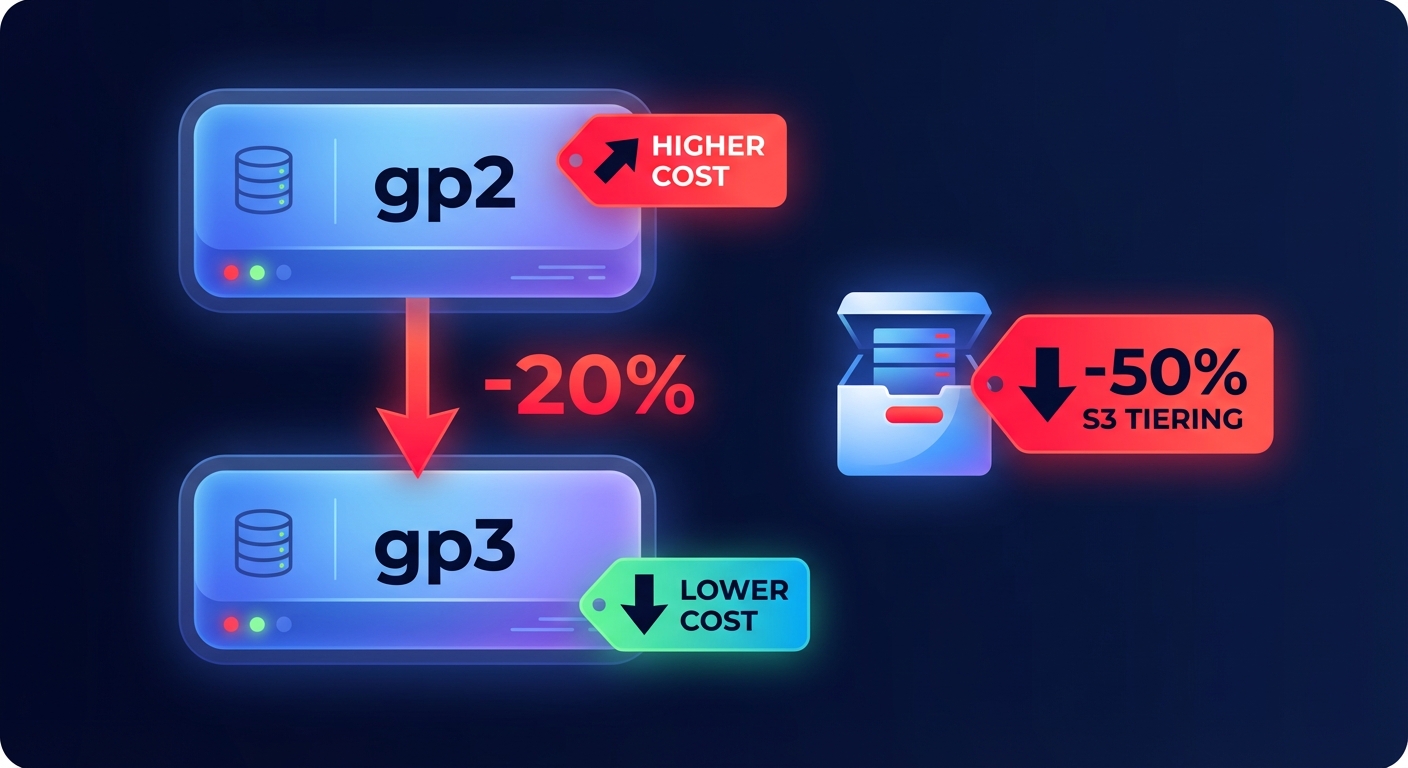
For object storage, AWS S3 cost optimization relies heavily on S3 Intelligent-Tiering. This service automatically moves data between frequent and infrequent access tiers based on actual usage patterns, which can slash storage bills by 50% without any performance impact. For long-term retention, moving cold data to Glacier Deep Archive is approximately 23 times cheaper than S3 Standard, costing just $0.00099 per GB in certain regions.
Networking: Optimizing data transfer and egress
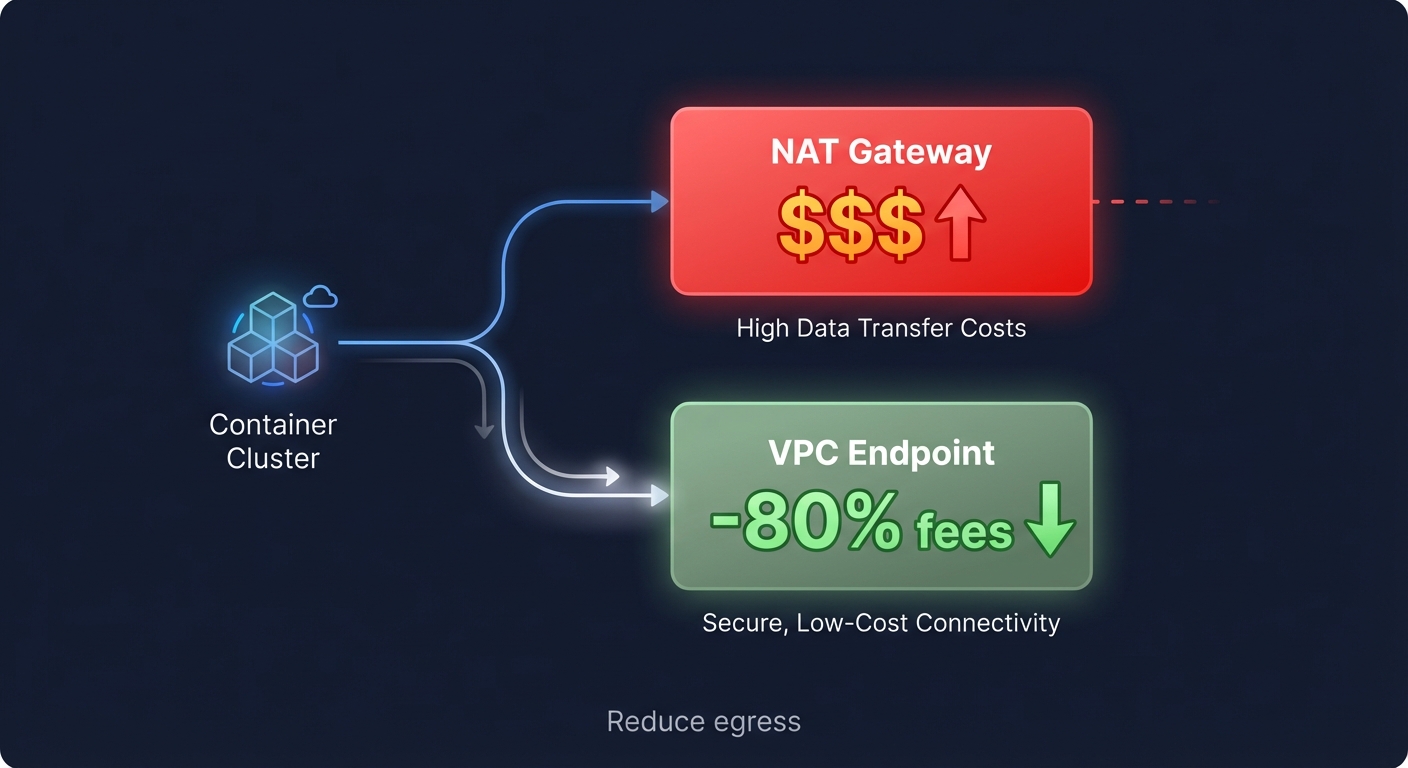
Networking costs are often a “hidden tax” that can devour 25% to 35% of a cloud budget. High-volume container workloads often rack up massive AWS NAT Gateway costs simply by pulling images from ECR or communicating with S3. Replacing NAT Gateways with VPC Endpoints can lead to an 80% reduction in data processing fees for these specific traffic patterns.
Furthermore, AWS egress costs – the fees for data leaving your VPC – can be minimized by co-locating resources within the same Availability Zone (AZ). Cross-AZ traffic often costs $0.01/GB in each direction, which can silently inflate budgets in high-traffic microservice architectures. Using Amazon CloudFront for global content delivery can also help mitigate internet egress fees by caching content closer to your users. By aligning your architecture to keep data transfer local to an AZ whenever possible, you eliminate redundant charges and improve application latency.
Governance through allocation and auditing
You cannot optimize what you do not measure. A robust AWS cost allocation tags strategy is essential for converting a monolithic invoice into actionable data. By tagging resources with metadata such as “Owner,” “Environment,” and “ApplicationID,” you can hold individual teams accountable and identify which specific services are driving spend. This visibility prevents “unallocated” line items from consuming up to 50% of your cloud budget.
Regularly conducting a cloud cost audit allows you to find “zombie” resources, such as Elastic IPs not attached to instances or load balancers with zero active connections. These small leaks collectively add up to thousands of dollars in monthly waste. Using tools like AWS Cost Explorer and AWS Trusted Advisor can help identify these low-hanging fruits for immediate remediation. Setting up AWS cost anomaly detection is also critical to catch misconfigured resources, like a Lambda function stuck in an expensive loop, before they balloon into a five-figure surprise at the end of the month.
Putting optimization on autopilot with Hykell
The practices outlined above – right-sizing EC2, migrating to gp3, and refactoring NAT traffic – are highly effective, but they require constant manual effort. As your infrastructure scales, manual optimization becomes a full-time engineering burden that slows down innovation. Hykell provides the “autopilot” layer for your AWS infrastructure, integrating directly with your environment to continuously identify and execute these optimizations in real-time.
Whether it is accelerating your transition to Graviton or automating your EBS performance tuning, Hykell handles the technical heavy lifting without requiring code changes or ongoing engineering lift. Our customers typically see a 40% reduction in their overall AWS spend by moving from reactive firefighting to proactive, automated cost control.
Because we operate on a performance-based model, you only pay a slice of what you actually save. If our platform does not find savings, you do not pay. Experience the power of automated FinOps and turn your cloud infrastructure into a lean, high-performance asset. Calculate your potential savings with Hykell today and start optimizing your AWS resource allocation on autopilot.