
Is your AWS infrastructure running as fast as it costs? Most engineering leaders over-provision resources by nearly 35% because they lack the granular performance data needed to scale down safely. Establish a rigorous benchmarking framework today to decouple high performance from high spending.
Establishing your AWS performance baselines
Before you can optimize, you must understand your “normal.” Practical benchmarking begins by establishing clear baselines using consistent testing environments. A baseline is like a routine health checkup; it is impossible to diagnose a performance drop if you do not know what a healthy system looks like. To minimize network variability and “noisy neighbor” effects, you should always run benchmarks in the same Availability Zone and utilize EBS-optimized instances to ensure dedicated bandwidth for your storage traffic.
Effective testing falls into three categories: synthetic, real-world, and hybrid. Synthetic tests provide a clean look at raw limits, while real-world scenarios – which often involve replaying production traffic – reveal how your application handles concurrency and resource contention. For big data workloads, adopting industry standards like TPC-DS ensures your results are comparable to the broader ecosystem. Regularity is vital to success; while quarterly reviews are standard for many, mission-critical systems often require monthly benchmarking to stay ahead of architectural drift and unexpected scaling costs.
Essential metrics for cloud efficiency
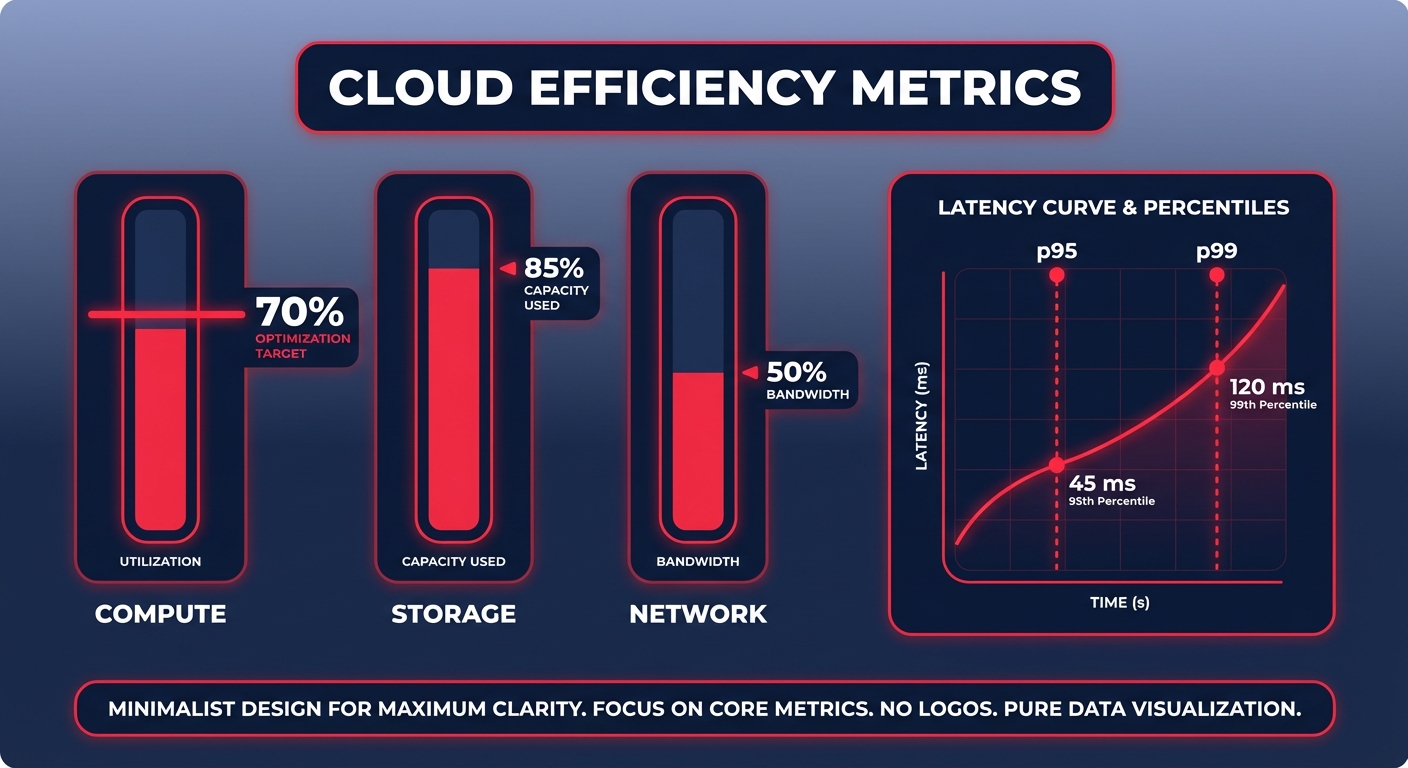
A successful benchmarking strategy focuses on the three pillars of infrastructure: compute, storage, and network performance. When evaluating compute resources, you are not just looking at vCPU counts. You must measure CPU utilization and memory pressure. A common engineering threshold for CPU utilization is 70%; anything consistently lower suggests you are paying for idle capacity that could be reclaimed.
Storage performance acts as the primary bottleneck for databases and I/O-intensive applications. You need to measure latency (TTFB), throughput in MiB/s, and IOPS. For many organizations, migrating from gp2 to gp3 volumes delivers 40% better performance at 15% lower cost because gp3 allows you to provision throughput independently of storage size. On the networking side, keep a close eye on inter-AZ latency and bandwidth, particularly if your architecture relies on distributed microservices that frequently communicate across boundaries.
Interpreting results and identifying bottlenecks
Data without interpretation is just noise. When you analyze your results, focus on the “p95” and “p99” latencies rather than averages. Averages often hide the performance “cliffs” that frustrate your users. If you observe high storage latency, check your VolumeQueueLength in CloudWatch. A queue length consistently above 10 typically indicates that your application is waiting on I/O, suggesting you need more provisioned IOPS or a transition to io2 Block Express.
Another critical metric is the performance-to-cost ratio. By calculating the “cost per request,” you can see if a more expensive instance family actually provides better unit economics for your specific workload. For example, migrating to AWS Graviton instances can improve price-performance by up to 40% over x86 counterparts. However, you only realize these gains if your workload is optimized for the ARM architecture and you have benchmarked the performance increase against the cost of the migration.
Systematic tuning without performance degradation
Once you identify your bottlenecks, tuning should be a surgical process. Start with right-sizing your environment. You can use AWS Compute Optimizer to find the 20-30% of your instances that are likely over-provisioned. After addressing compute, focus on storage by standardizing on gp3 to save approximately 20% per GiB compared to gp2 while eliminating the risk of burst-credit exhaustion.
For networking, implementing placement groups can drastically reduce latency for tightly coupled workloads. However, manual tuning is a never-ending cycle that consumes valuable engineering hours. Many teams find that while they can achieve initial wins, maintaining those gains against changing traffic patterns is nearly impossible without automation. This is where a systematic approach to AWS rate optimization and automated resource management becomes necessary to ensure your costs do not climb back up over time.
Automating optimization with Hykell
Benchmarking proves that you can do more with less, but Hykell actually implements those changes for you. Hykell provides automated cloud cost optimization that reduces your AWS spend by up to 40% without compromising the performance baselines you have established. Instead of manual right-sizing and constant monitoring, Hykell operates on autopilot to identify underutilized resources and apply rate strategies that minimize your commitment risk.
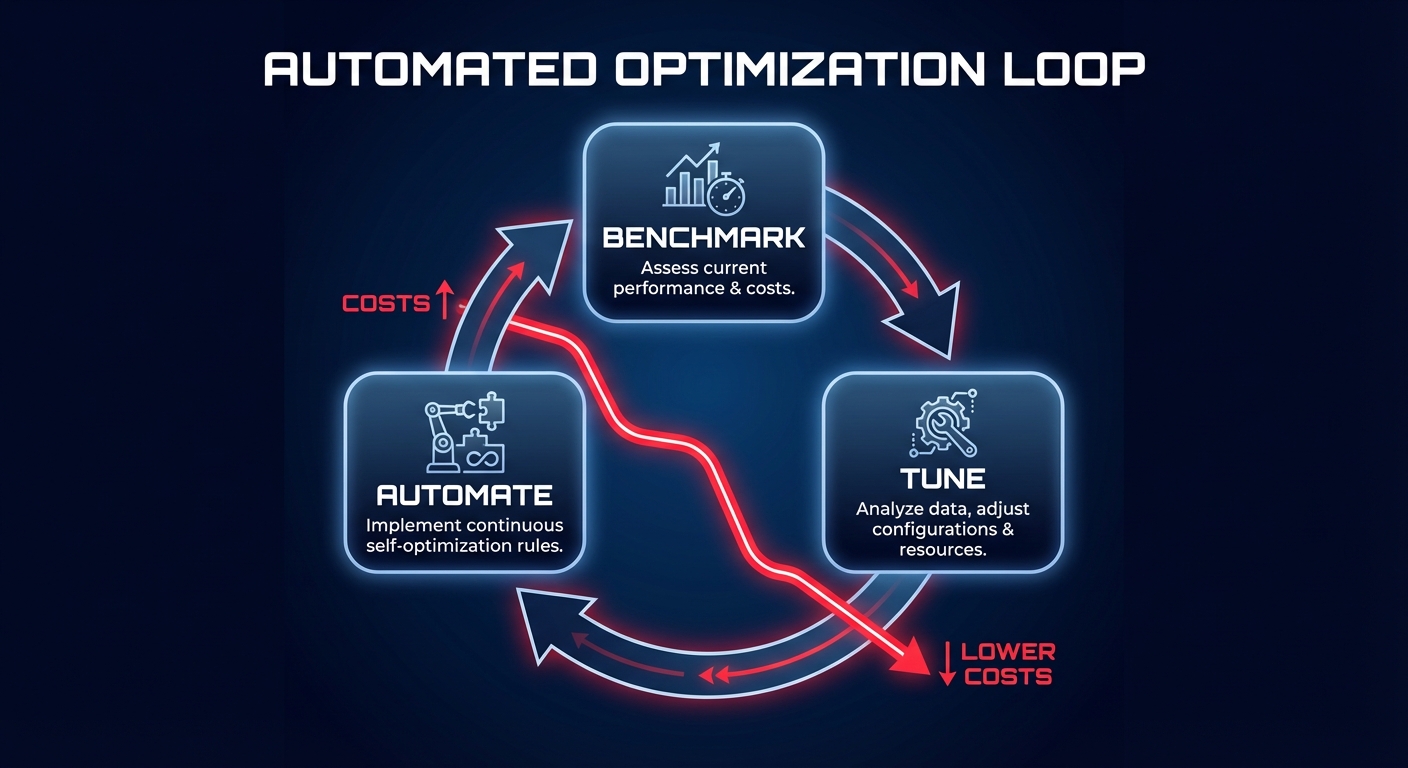
The platform integrates directly with your existing environment, requiring zero code changes or engineering effort. Because Hykell only takes a slice of what you actually save – if you don’t save, you don’t pay – it aligns perfectly with your goal of increasing efficiency. You receive real-time monitoring and actionable insights that turn your benchmarking data into immediate financial results.
Stop guessing your performance limits and start optimizing with precision. See how much you could save on AWS with Hykell and book a detailed cost audit today to reclaim your cloud budget.

