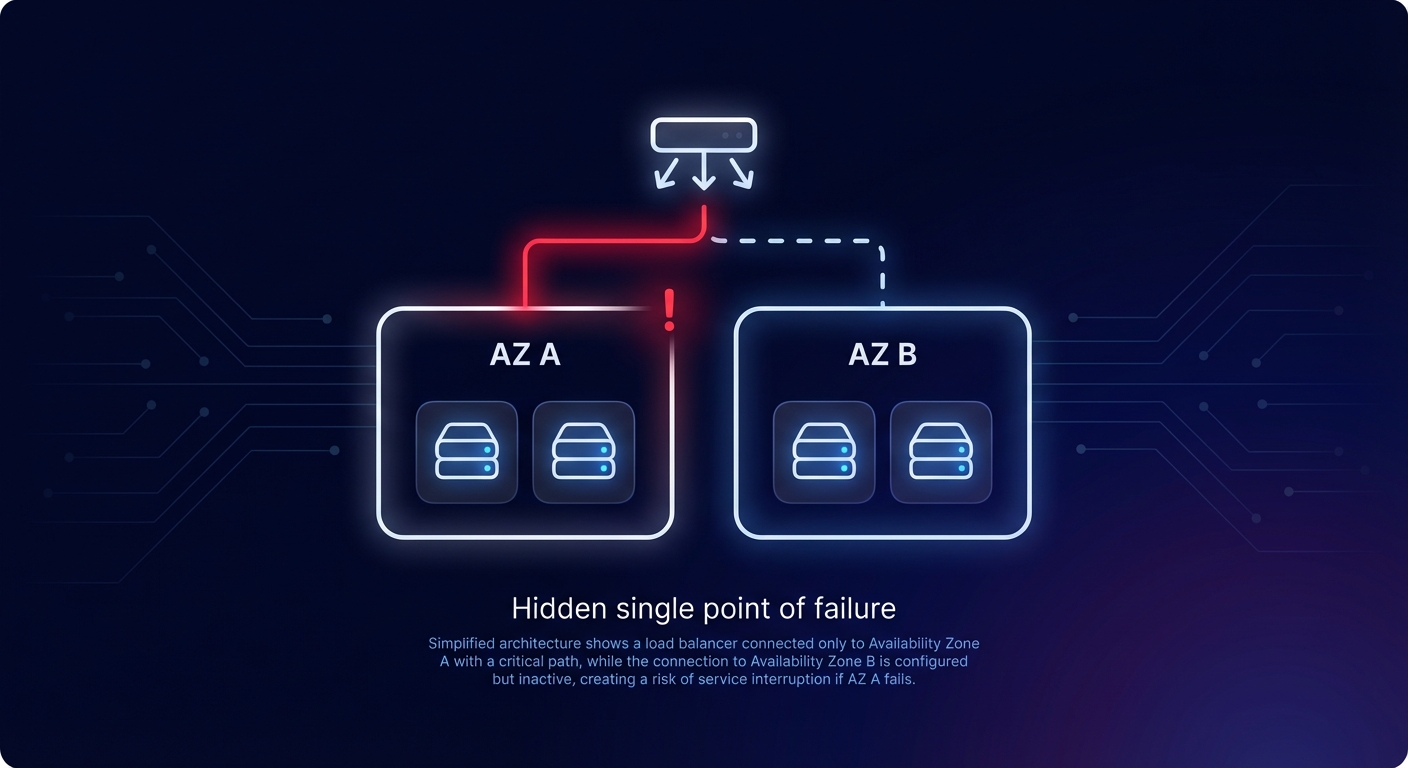
Is your multi-AZ architecture actually resilient, or are you just paying for a label? Many engineering teams assume their AWS infrastructure is redundant, but hidden single points of failure in unmonitored subnets create massive risks during regional outages while inflating your monthly cloud bill.
AWS Trusted Advisor serves as your primary automated auditor, evaluating your environment against five critical pillars: cost optimization, performance, security, fault tolerance, and service limits. For mid-market and enterprise organizations, the fault tolerance category is particularly vital. These checks provide the technical evidence required for governance audits and help when you are conducting a cloud cost audit by ensuring you aren’t overspending on “high availability” that does not actually exist.
Why fault tolerance is a critical FinOps priority
Engineering managers often view fault tolerance through the lens of uptime, but for FinOps leads, it is a matter of resource efficiency. If you pay for multiple Availability Zones (AZs) but your Application Load Balancers (ALBs) or VPC interface endpoints are only configured for one, you effectively waste a significant portion of your networking budget.
Integrating fault tolerance checks into your FinOps framework allows you to validate that the premium paid for redundancy delivers the intended resilience. Recent updates to Trusted Advisor throughout 2023 and early 2024 added specific checks for ALB and NLB Multi-AZ configurations, ensuring that your entry points are as resilient as the instances behind them. By maintaining high AWS performance SLAs, you avoid the business costs of failure while maximizing the value of every dollar spent on multi-region infrastructure.
Navigating the 2024 landscape of fault tolerance checks
AWS has significantly expanded the depth of its fault tolerance category to cover complex database and container configurations that directly impact cloud resource utilization analysis. While Basic Support users can access a selected set of checks, teams with Business or Enterprise Support plans gain full access to the complete library of 482 checks across 19 regions.
Monitoring these checks ensures your environment adheres to the AWS Well-Architected Framework and supports ongoing AWS performance benchmarking. Key fault tolerance checks you should monitor regularly include:

- Amazon ECS Multi-AZ placement: This identifies services not utilizing multiple AZs, which is critical for maintaining container availability during a zone failure.
- RDS ReplicaLag, FreeStorageSpace, and DiskQueueDepth: These metrics identify when your secondary databases fall behind, potentially rendering your failover strategy useless.
- Direct Connect location resiliency: For enterprises with hybrid setups, this ensures your physical connection to AWS is not a single point of failure.
- Amazon DocumentDB Single-AZ clusters: This identifies clusters lacking a high-availability instance, a common source of risk in environments that migrated from development to production without architectural updates.
- Route 53 Resolver Endpoint Redundancy: This validates that your DNS resolution remains available even if a specific AZ experiences an outage.
Closing the loop with observability and usage statistics
Fault tolerance checks should not exist in a vacuum; they function best as part of a broader observability strategy. While Trusted Advisor flags a risk, AWS CloudWatch application monitoring provides the real-time telemetry needed to understand why a policy breach occurred. For example, if Trusted Advisor warns of low available IPs in subnets for your Auto Scaling groups, CloudWatch help you visualize the scale-out events that led to the shortage.
This data-driven approach is essential for establishing AWS KPIs that link operational health to financial governance. Mature teams often integrate these checks with AWS Resilience Hub, which provides a resilience score to quantify risk. A score of 70 or above indicates a healthy, green status, while scores below 40 signal red flags that require immediate architectural remediation to meet your Recovery Time Objective (RTO) targets.

By analyzing AWS CloudWatch logs and usage statistics, you can determine if a service truly requires Multi-AZ deployment or if a single-AZ setup with automated recovery is sufficient for its business tier. Many organizations find they are over-provisioned in non-production environments. You can choose to accept the “risks” flagged by Trusted Advisor to save costs, provided your AWS cost allocation tags clearly mark the environment as “Development.” This is where Trusted Advisor cost optimization checks overlap with fault tolerance to help you find the most efficient spending level.
Automating cloud resilience without the engineering overhead
Relying on manual reviews of Trusted Advisor is a recipe for configuration drift. For mid-market and enterprise companies, the sheer scale of resources makes human-led auditing nearly impossible to maintain. Automated cost optimization has become the standard for high-performing AWS teams who need to balance reliability with financial efficiency.
Hykell provides an automated solution that monitors your environment around the clock, identifying underutilized resources and implementing optimizations on autopilot. While Trusted Advisor alerts you to a problem, Hykell closes the loop by automatically optimizing EC2, EBS, and RDS instances to ensure you only pay for the capacity you actually need.
By combining Hykell’s AWS rate optimization – which can boost effective savings rates to 50–70% – with the architectural safeguards found in Trusted Advisor, you can reduce your total AWS bill by up to 40% without ever touching a line of code or sacrificing the resilience of your production workloads.
Stop leaving your cloud resilience and savings to chance. Schedule a free cloud cost audit with Hykell today and discover how automated intelligence can harden your infrastructure while slashing your monthly bill.

