Is your AWS bill a “waste tax” on your engineering velocity? Most mid-market and enterprise teams leave 30–40% of their potential savings on the table because they treat discounts as a procurement task rather than a continuous technical strategy.
The AWS discount hierarchy: From free tier to enterprise agreements
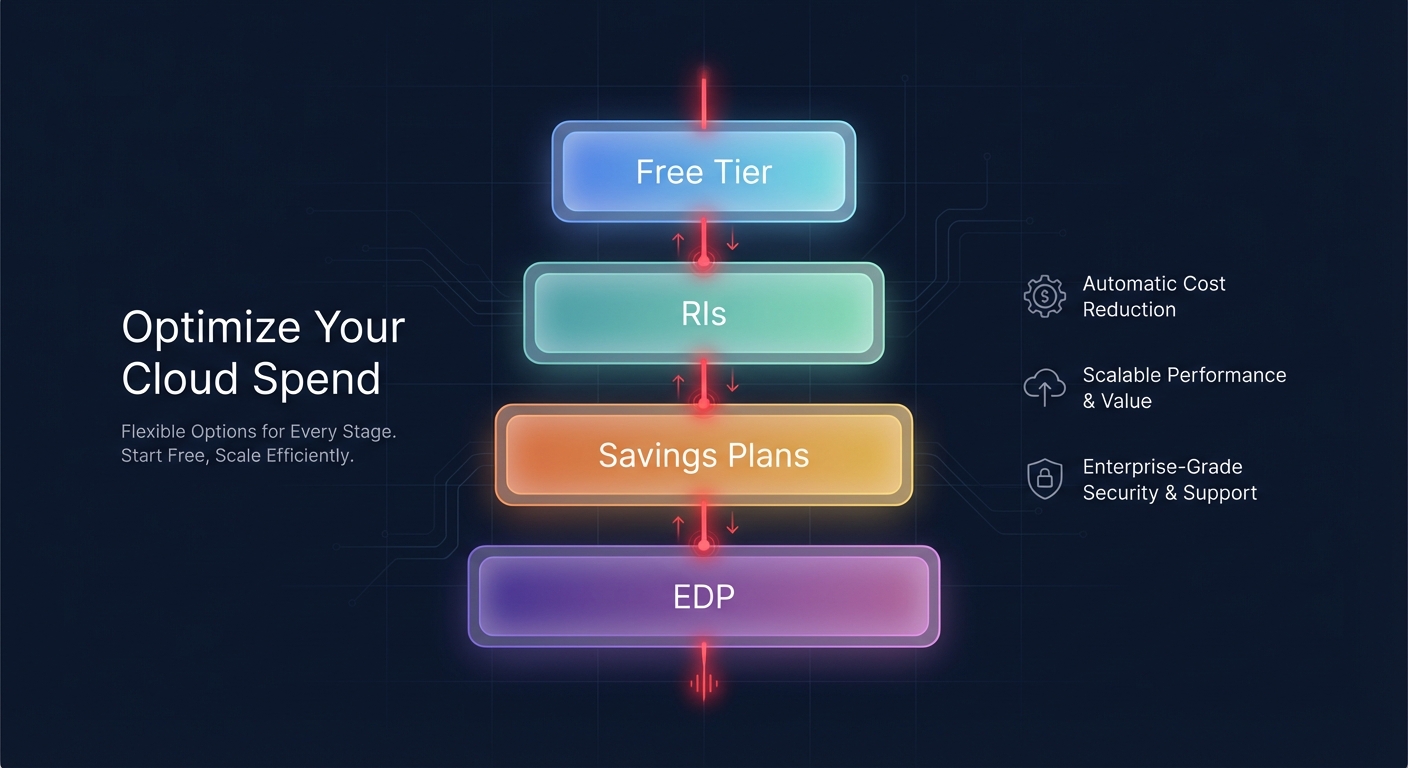
Navigating AWS discounts requires a layered approach where you stack mechanisms rather than choosing just one. Most organizations begin with basic free offerings and graduate toward complex enterprise discount programs (EDP). However, the real strength of your financial operations lies in how you manage the middle layers of commitments to improve your Effective Savings Rate (ESR).
AWS free tier and promotional credits
The AWS free tier serves more than just startups; it is a vital tool for established enterprises testing new architectures. This program operates on three models: Always Free, 12-month Free, and short-term Trials. For instance, Amazon Lambda provides a permanent free tier of 1 million requests and 400,000 GB-seconds of compute time monthly. While these credits might not significantly impact a massive enterprise bill, they allow your team to experiment with serverless components without immediate overhead. Beyond the standard free tier, you can often secure promotional credits through the migration acceleration program (MAP) when transitioning large-scale workloads from on-premises environments or other cloud providers.
Compute savings plans and reserved instances
Savings Plans and Reserved Instances (RIs) are the core pillars of cost reduction, offering discounts that can reach up to 72% in exchange for a one-year or three-year commitment. Compute savings plans have become the modern standard because they apply automatically across EC2, Fargate, and Lambda, providing up to 66% savings regardless of region or instance family.
For workloads that require specific capacity guarantees in a particular Availability Zone, standard RIs remain highly effective. Unlike Savings Plans, which are strictly “use it or lose it,” standard RIs offer unique liquidity. If your architectural needs change, these commitments can be sold on the AWS reserved instance marketplace to recoup value from otherwise stranded capacity.
Private pricing term sheets and EDPs
Once your annual cloud spend crosses the $1 million threshold, you qualify for a negotiated contract known as an Enterprise Discount Program (EDP). This agreement provides a flat discount, often ranging from 4% to 15%, across nearly all AWS services. The primary risk with an EDP is committing based on “dirty” spend that includes waste. Before entering negotiations, you must ensure your cost allocation tags are robust. Failing to clean up oversized idle instances or orphaned volumes before signing can lock you into paying for inefficiencies for the duration of a multi-year contract.
Bulk exam and certification vouchers
Engineering leaders can also reduce the cost of team professional development through bulk voucher programs. By purchasing certification vouchers in volume, organizations typically secure 10–20% discounts. These programs are usually accessible through the AWS Training and Certification portal or as a benefit for members of the AWS Partner Network (APN).
How to qualify and stack for maximum impact
Reaching the 40% savings mark requires a precise understanding of how AWS applies these discounts to your bill. AWS follows a specific order of operations: Reserved Instances are applied first, followed by Savings Plans. Only after these commitment-based discounts are calculated does AWS apply the negotiated EDP discount to the remaining blended rate. To maximize this impact, you should incorporate a variety of pricing models across your infrastructure:

- Utilize Spot Instances for fault-tolerant, stateless workloads like batch processing or CI/CD to capture 70–90% savings.
- Cover steady-state baseline usage with 3-year Savings Plans or RIs to secure 55–72% discounts.
- Layer an Enterprise Discount (EDP) on top of your total spend once you reach the $1M annual commitment threshold.
- Migrate ARM-compatible application code to Graviton instances to achieve an additional 20–40% in price-performance gains.
A common mistake for enterprise leaders is over-relying on one-year Savings Plans. While these feel lower risk, they often cap your savings at 20–25% and provide zero flexibility once purchased. Effective rate optimization requires a mix of instruments that can adapt to changing resource demands.
Reaching 40% savings on autopilot with Hykell
Maintaining high savings levels is difficult because manual commitment management often diverts engineering talent away from product development. Most teams find it impossible to manually calculate RI coverage ratios or time marketplace sales perfectly as workloads shift. Hykell solves this by layering automated optimization on top of your existing AWS discounts, bridging the gap between basic coverage and maximum efficiency.
The platform uses AI-powered commitment blending to manage an algorithmic mix of RIs and Savings Plans. This approach allows you to capture the high discount rates associated with 3-year terms – up to 72% – without the traditional lock-in risk. The system automatically buys, sells, and converts these instruments in real-time. Additionally, Hykell handles zero-engineering right-sizing by identifying over-provisioned resources and orphaned EBS volumes that native AWS tools frequently overlook.

By combining a negotiated EDP with Hykell’s automated rate optimization, enterprise companies can stop overpaying for the cloud and boost their ESR to 50–70% on compute workloads. Hykell operates on a performance-based model, meaning you only pay a portion of the actual savings realized. Calculate your potential AWS savings today and stop leaving your uncaptured discounts on the table.

