
Are you still paying an “x86 tax” on your AWS bill? Migrating to AWS Graviton instances can slash compute costs by up to 40% while boosting performance. This guide explores how to integrate these ARM-based processors into your Auto Scaling Groups and EKS clusters without disrupting production.
When you introduce Graviton into an autoscaling environment, you are doing more than just swapping instance types; you are managing a multi-architecture infrastructure that requires careful coordination between your application builds and your scaling policies. Navigating this shift effectively requires a deep understanding of launch templates, capacity weighting, and automated migration patterns.
The foundation of Graviton Auto Scaling
To use Graviton in an Auto Scaling Group (ASG), you must first ensure your application is compiled for the ARM64 architecture. While interpreted languages like Python, Node.js, and Java typically run without code changes, your underlying Amazon Machine Image (AMI) must be Graviton-compatible. This architectural shift often acts as a catalyst for modernization, pushing teams toward more efficient containerized workflows.
Launch templates and AMI selection
In a standard ASG, the launch template defines the AMI. Because an AMI is architecture-specific – either x86_64 or ARM64 – you cannot simply list an m5.large and an m6g.large in the same mixed instances policy if they require different AMIs. For teams utilizing Kubernetes optimization on AWS, the best practice involves creating separate node groups for different architectures. This allows you to use architecture-specific AMIs while leveraging Kubernetes labels and taints to ensure pods land on the correct hardware.
Configuring mixed architecture and capacity weighting
Running a large-scale fleet often requires mixing instance families to improve availability and cost. AWS allows you to define a Mixed Instances Policy within your ASG, which is particularly effective when combining Spot Instances and Graviton. This approach provides a safety net, allowing your infrastructure to fall back to On-Demand or x86 instances if the primary ARM capacity becomes scarce.
Capacity weighting for heterogeneous fleets
Not all vCPUs are created equal. When mixing different generations – such as Graviton2 (m6g) and Graviton3 (m7g) – you should use capacity weighting. This feature tells the ASG exactly how much “weight” each instance type contributes toward your desired capacity.
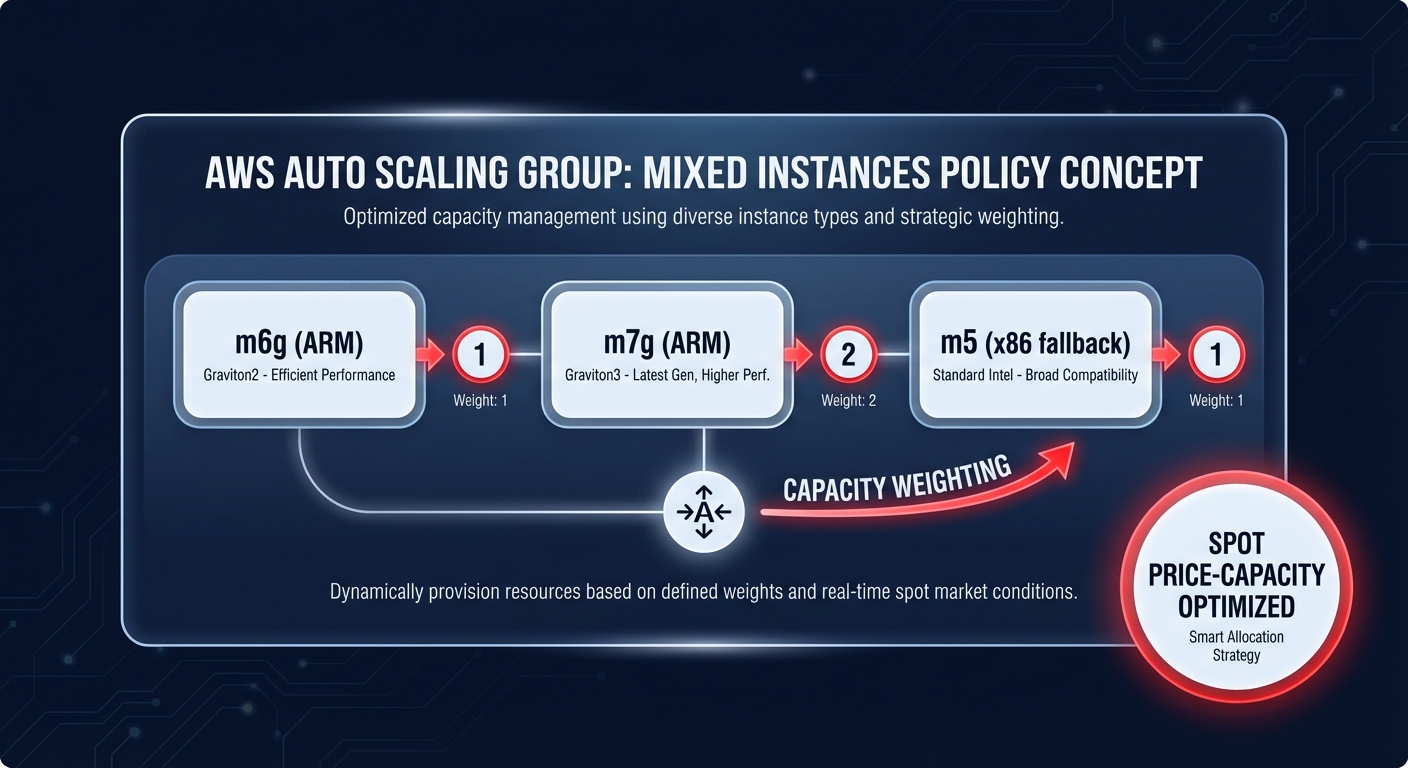
- If an m6g.large is your baseline (weight 1), you might assign an m7g.xlarge a weight of 2.
- This ensures that as the ASG scales, it understands the specific compute power being added, regardless of the instance type provisioned.
- Proper weighting prevents over-provisioning when the ASG selects larger instances from the pool to satisfy a scaling event.
Spot allocation strategies
To maximize savings, you should utilize the price-capacity-optimized allocation strategy. This instructs AWS to prioritize Spot pools with the highest availability that also offer the best price. Since Graviton instances often have deeper Spot pools than over-subscribed x86 families, this strategy naturally favors ARM-based capacity, lowering your bill while maintaining high stability.
Migrating EKS workloads to Graviton
For Kubernetes users, the migration to Graviton is increasingly handled through Karpenter for AWS Kubernetes scaling, which has largely superseded legacy scaling tools for complex, mixed-architecture needs. Successful migrations rely on multi-architecture container images created via tools like Docker Buildx, which allow a single deployment manifest to serve nodes regardless of their underlying CPU.
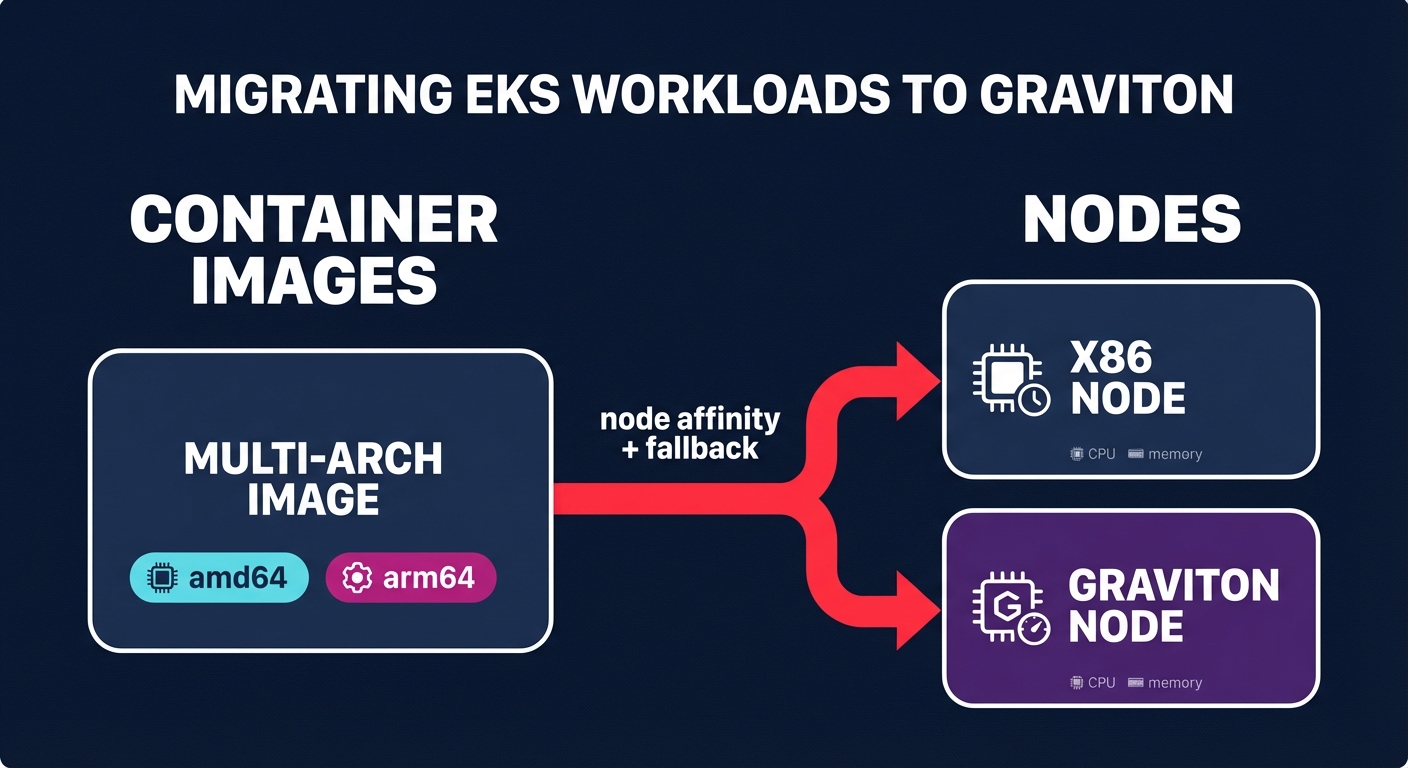
Once images are ready, engineers can use node affinity in pod specifications to prefer Graviton nodes. This allows you to test Graviton in production by “bleeding” a small percentage of pods onto ARM nodes while keeping the rest on x86. For high availability, you must configure fallback patterns that allow the provisioner to revert to x86 capacity if ARM availability becomes constrained in a specific region.
Common pitfalls and performance hurdles
While Graviton offers a significant price-performance ratio compared to traditional instances, it is not a “silver bullet” for every workload. You should be aware of technical nuances that can impact your ROI:
- Single-Threaded Performance: While Graviton excels at multi-threaded, scale-out workloads, some legacy single-threaded applications may still perform 6–14% better on high-clock Intel x86 instances.
- Memory Bandwidth: Newer generations like Graviton3 and Graviton4 provide up to 50% faster memory access than Graviton2. This makes them superior for memory-intensive databases, but you must benchmark your specific application to see the real-world gain.
- Binary Dependencies: If your application relies on proprietary x86-only binaries or specialized Intel instruction sets like AVX-512, migration may require significant re-engineering or emulation, which can negate immediate cost savings.
Automating Graviton gains with Hykell
Manually managing mixed-architecture groups, benchmarking performance, and adjusting capacity weights can place a heavy operational burden on SRE teams. Hykell removes this overhead by accelerating your Graviton gains through intelligent, data-backed automation.
The Hykell platform identifies the best candidates for migration by analyzing your real-world usage patterns. Beyond simple suggestions, Hykell helps you optimize your AWS rate by stacking Graviton’s lower hourly costs with automated Savings Plans and Reserved Instance management. This autopilot approach ensures you never pay for idle capacity or inefficient x86 resources.
Whether you are running stateless microservices in ASGs or complex EKS clusters, moving to Graviton is one of the most effective ways to lower your cloud TCO. By combining Graviton’s architectural efficiency with Hykell’s automated cost management, you can achieve up to 40% savings without touching a single line of code.
See how much you could save on your AWS bill by using the Hykell automated cloud cost optimization platform and start optimizing your infrastructure today.

