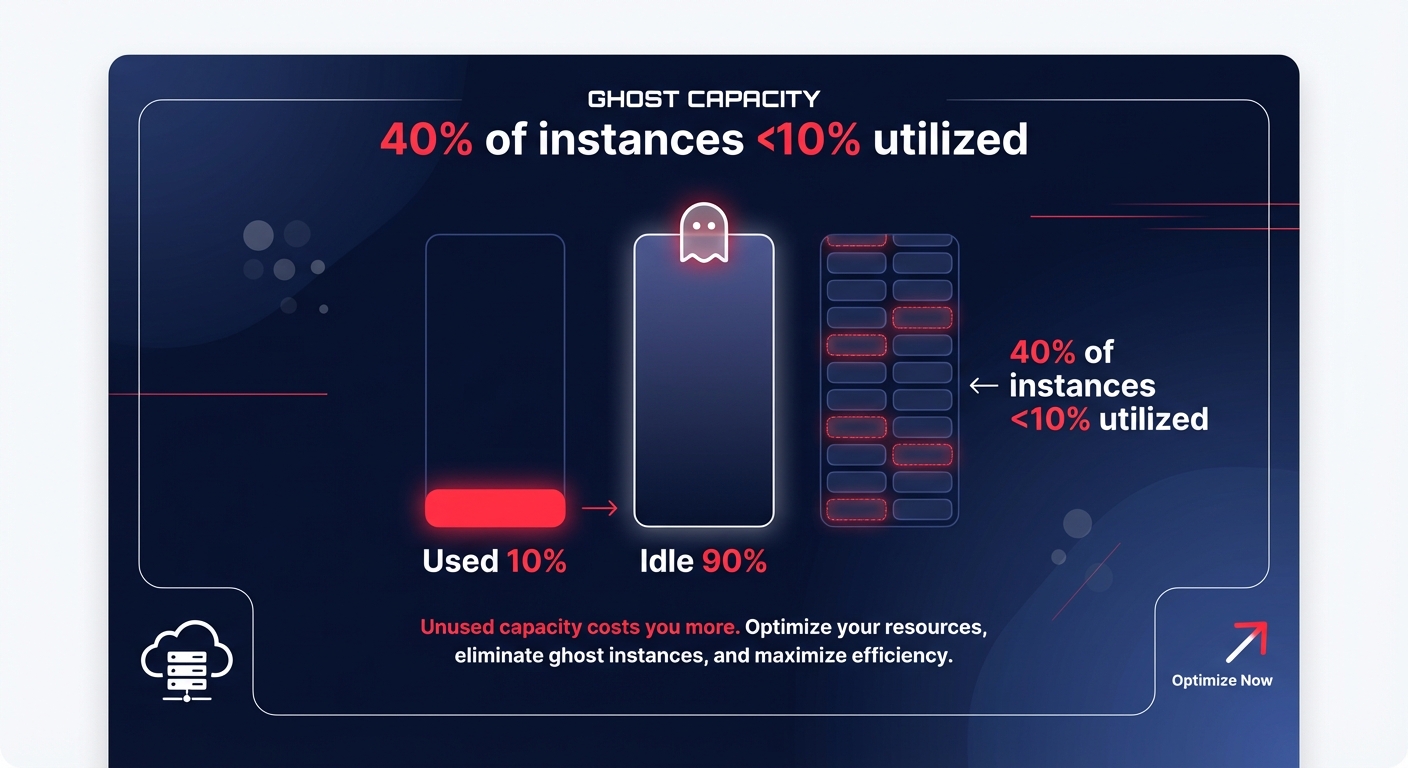
Are you paying for “ghost” capacity? With 40% of EC2 instances running at less than 10% utilization even during peak traffic, most engineering teams are wasting budget on idle resources. You can achieve high-performance cloud scalability without the excessive cost tax by shifting to automated efficiency.
What is cloud scalability on AWS?
Cloud scalability refers to the ability of your infrastructure to handle increasing workloads by adding resources. On AWS, this process is not merely about surviving a sudden traffic spike; it involves maintaining a consistent user experience while ensuring your AWS EC2 performance tuning remains cost-effective. While people often use the terms interchangeably, scalability differs from elasticity. Scalability describes the infrastructure’s capacity to grow, whereas elasticity is the ability of that infrastructure to shrink back down when demand subsides.
For engineering leaders, the ultimate goal is to design systems where performance and cost scale linearly. In a perfectly optimized environment, unit costs should actually drop as performance improves. Achieving this requires a deep understanding of how different AWS resources interact and how to avoid the common pitfalls that lead to “over-provisioning,” where teams pay for performance they never actually use.
Vertical vs. horizontal scaling: choosing your path
When an application hits its limits, you generally have two paths to increase capacity. Choosing between them is essential for maintaining system reliability and informing your broader AWS rate optimization strategy.

Vertical scaling (scaling up)
Vertical scaling involves adding more power, such as CPU, RAM, or IOPS, to an existing instance. In the context of AWS, this might mean moving a workload from a `t3.medium` to an `m6i.large`. This approach is simple to implement because it requires no architectural changes, making it ideal for relational databases or legacy applications that were not designed for distributed environments.
However, scaling up has significant drawbacks. It often requires downtime, particularly for RDS instances, and creates a single point of failure because your entire workload still relies on a single node. While AWS Aurora performance tuning handles vertical scaling more gracefully through rolling upgrades, it remains a short-term solution because every instance eventually hits a hardware ceiling.
Horizontal scaling (scaling out)
Horizontal scaling adds more instances to your resource pool rather than making a single instance larger. This might involve adding nodes to an EKS cluster or increasing the task count in an ECS service. This strategy offers nearly limitless growth and enhanced fault tolerance; if one node fails, the remaining instances continue to process requests.
While this is the preferred long-term solution for microservices and web servers, it does increase operational complexity. Horizontal scaling requires sophisticated load balancing, state management, and a focus on Kubernetes optimization on AWS to ensure that adding more nodes does not lead to a corresponding explosion in management overhead or wasted capacity.
Key architectural patterns for efficient scaling
To scale efficiently, you must move beyond the habit of simply adding more servers. High-performing teams leverage specific AWS architectural patterns to balance throughput with expense, ensuring that every dollar spent contributes to application performance.
The most effective starting point is to right-size your environment before you attempt to scale it. Scaling an over-provisioned environment is the fastest way to deplete your budget, as you are essentially duplicating waste. Research indicates that right-sizing cloud resources can unlock 20–40% cost savings immediately. Before configuring your AWS EC2 auto scaling best practices, you must ensure your baseline instances are not sitting idle.
Processor choice also plays a massive role in scaling efficiency. Migrating to Arm-based AWS Graviton instances provides a 15–25% cost advantage for CPU-bound workloads. Because Graviton offers superior compute density, you can often handle the same request volume with smaller or fewer instances compared to traditional x86 architectures, providing a better price-performance ratio.
Storage throughput is another frequent bottleneck that is often mistaken for a CPU issue. Migrating from gp2 to gp3 volumes delivers 20–30% lower costs while allowing you to provision IOPS and throughput independently. A clear understanding of AWS EBS throughput limits ensures that your instances are not throttled during peak scale-out events, which could otherwise lead to artificial performance degradation.
Finally, as you scale horizontally, you must address the “chatty” service problem to control networking expenses. Data transfer between Availability Zones (AZs) costs $0.01/GB, which can cause AWS egress costs to skyrocket in a distributed architecture. By co-locating microservices within the same AZ or utilizing AWS NAT Gateway cost optimization through VPC Endpoints, you can reduce networking fees by up to 80% without impacting application availability.
The role of automation in scalable design
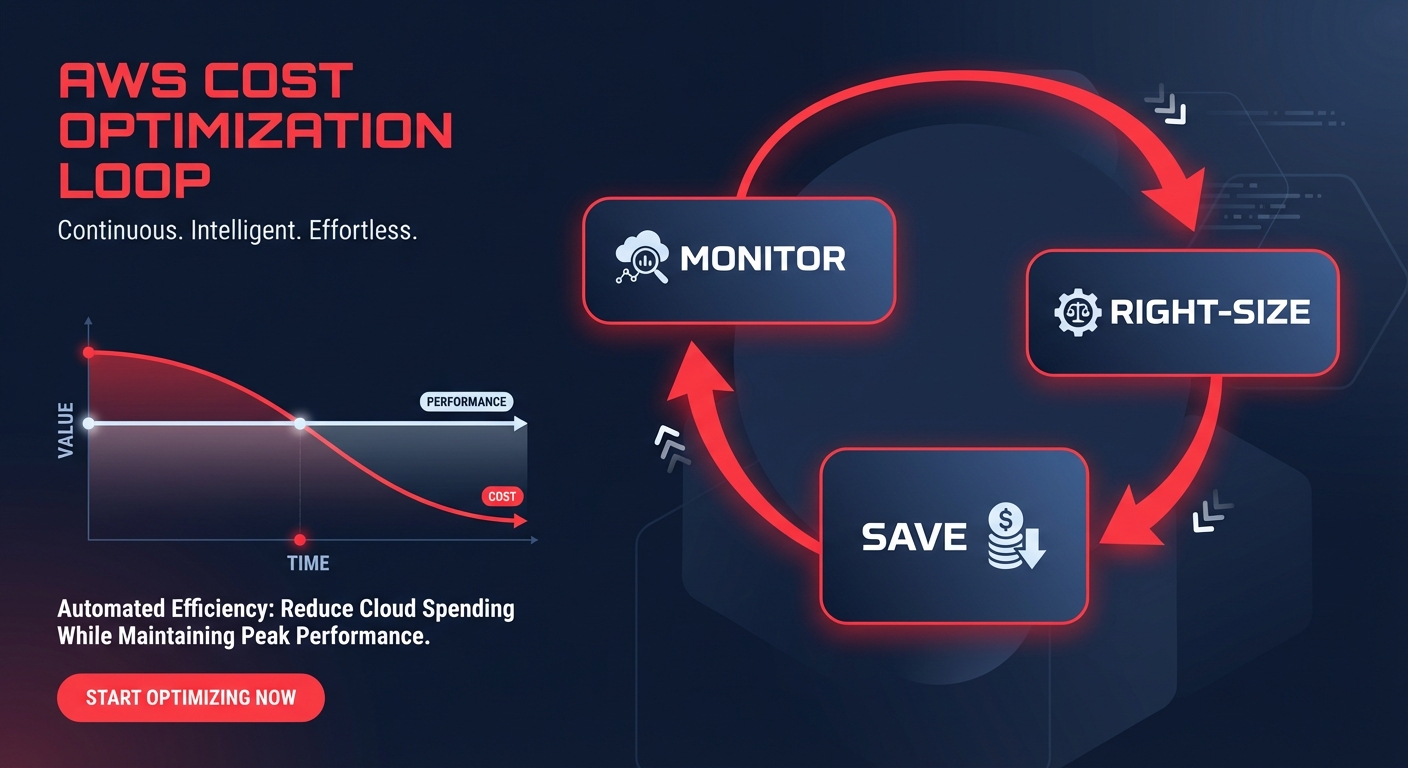
The primary challenge with manual scaling is that human engineers cannot react to real-time telemetry fast enough to prevent waste. By the time a manual audit identifies an oversized instance, you have already paid for weeks of idle capacity. This is where Hykell provides a critical advantage by operating as an automated intelligence layer over your AWS infrastructure.
Hykell monitors your environment in real-time to identify cloud cost anomalies and underutilized resources. Instead of burdening your DevOps team with constant manual reviews, the platform uses automation to manage the complexities of a scalable architecture:
- Right-sizing occurs on autopilot, matching instance types to actual workload requirements without compromising performance.
- The system builds an algorithmic mix of Savings Plans and Reserved Instances that adapt automatically as your application scales out or in.
- Storage and container orchestration layers are continuously optimized to target an ideal 85% cluster utilization, significantly reducing the “empty space” in your EKS or ECS environments.
Efficient scaling is no longer just a technical requirement; it is a financial imperative. When you design for horizontal growth, right-size your baseline, and use automation to handle the intricacies of AWS pricing models, you transform your infrastructure from an expensive burden into a competitive advantage.
To see how much waste is hidden in your current environment, you can use our AWS cost savings calculator to uncover immediate opportunities. Hykell helps you reduce AWS costs by up to 40% through automated optimization, and because we only take a slice of what you save, there is no risk to your budget.

