
Does your AWS architecture actually meet the reliability promises you need—and how much are you paying for guarantees you might never use?
AWS publishes Service Level Agreements that define uptime commitments, service credits, and the penalties when those promises fail. For cloud engineering, FinOps, and compliance teams, these SLAs aren’t abstract—they shape risk, architecture decisions, and cost. Understanding what AWS guarantees (and what it excludes) helps you right-size resilience, plan for failure, and avoid overprovisioning in pursuit of an SLA your business doesn’t need.
What AWS SLAs actually promise
AWS provides separate SLAs for each of its services, with over 300 distinct SLAs published for paid, generally available services. Each SLA defines a Monthly Uptime Percentage—measured over the billing cycle—and specifies the service credit you’re entitled to when AWS falls short.
Standard uptime commitments for core infrastructure services typically range from 99.9% to 99.99%. That difference matters. A 99.9% commitment allows up to 7 hours 12 minutes of downtime per month, while 99.99% allows just 4.32 minutes. Amazon EC2 guarantees a 99.99% Monthly Uptime Percentage when instances are deployed across multiple Availability Zones. That commitment drives architectural patterns—and costs. Deploy everything multi-AZ and your bill goes up; skip it and your uptime guarantee drops or disappears entirely.
AWS measures these commitments using CloudWatch, which tracks availability metrics in real time. The SLA is based on aggregated data from CloudWatch over the month, so spikes, brief outages, and transient errors all count if they breach the threshold. For teams looking to instrument more comprehensive monitoring, AWS CloudWatch application monitoring offers dashboards, alarms, and anomaly detection to catch SLA violations before they escalate.
How service credits work (and what they don’t cover)
When AWS fails to meet an SLA, you’re entitled to a service credit—essentially a percentage refund applied to your monthly bill for that service. Credit tiers vary by severity. Amazon S3, for example, offers a 10% credit if monthly uptime falls below 99.9% and 25% if it drops below 99%. EC2 credits follow a similar tiered model, with higher credits for greater violations.
However, AWS SLAs exclude downtime caused by factors outside its control: customer misconfigurations (incorrect security groups, misconfigured routing), third-party software or integrations, and acts beyond AWS’s reasonable control (DDoS attacks, natural disasters). Service credits are applied automatically to your account unless you opt out, but here’s the catch—credits only compensate for AWS’s portion of the problem. If your application goes down because you deployed a single-instance architecture in one AZ and that AZ has an outage, AWS met its SLA for multi-AZ deployments. You just didn’t use it.
SLA commitments by service type
AWS structures SLAs around service categories, each with different guarantees and exclusions.
Compute SLAs
Amazon EC2 provides 99.99% uptime for instances deployed across multiple Availability Zones and 99.5% for single-instance deployments in a single AZ. The design choice directly affects both your SLA and your monthly compute costs—multi-AZ redundancy roughly doubles EC2 spend but quadruples the uptime commitment. AWS Lambda guarantees 99.95% uptime, measured by the percentage of requests that return errors within AWS’s control.
For teams optimizing compute workloads, AWS EC2 performance tuning offers practical guidance on right-sizing instances and improving efficiency without sacrificing reliability.
Storage SLAs
Amazon EBS guarantees 99.99% availability for volumes attached to EC2 instances within a single AZ. Amazon S3 commits to 99.9% uptime, with durability (the likelihood your data survives) separate at 99.999999999% (eleven nines) due to in-region replication.
If you’re evaluating Amazon EBS performance for latency-sensitive workloads, remember that SLA guarantees availability but not consistent IOPS or throughput under all conditions. Burst credits and provisioned IOPS matter more for predictable performance, and EBS benchmarking can help you verify whether your configuration meets your application’s needs.
Networking and load balancing
Elastic Load Balancing commits to 99.99% monthly uptime for Application, Network, and Gateway Load Balancers. The SLA measures whether the load balancer responds to requests, not whether your application behind it is healthy.
For teams working on cloud latency reduction techniques, note that SLA guarantees don’t address latency targets—only availability. If you need sub-10ms response times, architecture and instance tuning matter far more than the SLA.
Database and managed services
Amazon RDS offers a 99.95% SLA for Multi-AZ deployments and separate guarantees around automated backups. Single-AZ RDS instances do not receive an SLA commitment. DynamoDB guarantees 99.99% uptime for standard tables and 99.999% for global tables.
These SLAs assume proper configuration. If your RDS instance fails over during maintenance and your application doesn’t handle reconnections gracefully, AWS met its SLA—but your users still saw downtime.
How SLAs affect architecture and cost
SLA commitments shape your infrastructure in two ways: by dictating redundancy patterns and by influencing how aggressively you can optimize spend.
Multi-AZ designs increase cost but unlock higher SLAs
Deploying EC2 instances, RDS databases, and load balancers across multiple Availability Zones is the only way to access the higher SLA tiers. The trade-off is real. A single m6i.xlarge instance in one AZ costs roughly $140 per month. The same instance in two AZs for redundancy is approximately $280 per month. Cross-AZ data transfer adds another $0.01 per GB.
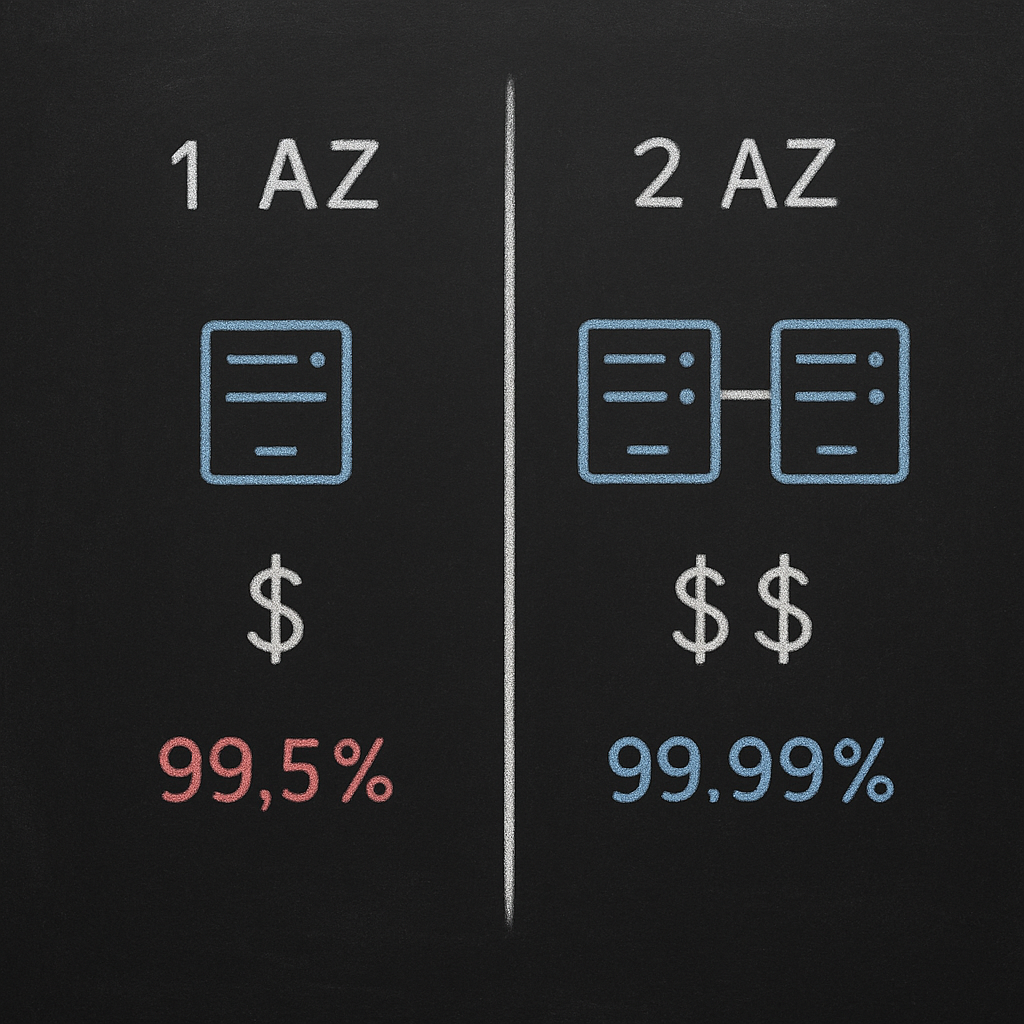
For workloads that can tolerate brief interruptions—batch processing, dev/test environments, analytics jobs—single-AZ deployments save money. For customer-facing APIs or transactional databases, multi-AZ becomes non-negotiable. Hykell’s AWS rate optimization helps balance these decisions by applying the right discount instruments (Reserved Instances, Savings Plans) to multi-AZ architectures without locking you into capacity you don’t need.
Overprovisioning for SLAs you don’t need wastes money
Not every workload requires 99.99% uptime. If your internal reporting dashboard can tolerate 30 minutes of monthly downtime, a 99.9% SLA is enough—and could cut infrastructure costs by 30–50% by avoiding unnecessary redundancy.
The real cost of downtime isn’t AWS’s service credit (usually 10–30% of the monthly charge). It’s lost revenue, failed transactions, and customer churn. Calculate your actual downtime cost per hour, then work backward to the appropriate SLA. If an hour of downtime costs you $10,000 and you run a service 24/7, 99.9% uptime allows up to 7 hours of downtime per month—potentially $70,000 in exposure. In that case, paying for 99.99% and multi-AZ resilience is justified. But if your workload only runs 8 hours a day and downtime costs $500 per hour, 99.9% is more than adequate.
For a broader understanding of how SLA commitments fit into overall performance management, see cloud performance SLAs.
Monitoring SLA compliance without heavy engineering lift
AWS tracks uptime using CloudWatch metrics, and you can automate SLA monitoring with minimal effort. Enable detailed CloudWatch metrics (costs roughly $0.30 per instance per month), set up CloudWatch alarms to track availability below SLA thresholds, and use CloudWatch Insights to aggregate uptime data across regions and accounts.
For broader visibility, AWS application performance monitoring provides tools to correlate performance metrics with business outcomes, helping you spot issues before they breach SLA thresholds. Hykell’s observability platform offers role-specific views that surface SLA compliance alongside cost impact, making it easy for FinOps and engineering teams to act on violations without manual reporting.
SLA exclusions and hidden gotchas
AWS SLAs include explicit exclusions that shift responsibility back to you. Scheduled maintenance doesn’t count against the SLA if AWS notifies you in advance. Configuration errors—security group misconfigurations, incorrect IAM policies, or bad routing tables—void the SLA. Third-party dependencies also fall outside the scope; if your app calls an external API and that API fails, AWS isn’t liable.
The most common gotcha: AWS measures SLA at the service level, not the application level. If your EC2 instances are up but your application crashes due to a code bug, AWS met its SLA. If your RDS instance is available but your queries time out because you didn’t provision enough IOPS, AWS met its SLA.
Understanding this distinction is critical when evaluating overall reliability. Your application’s uptime depends on architecture, monitoring, and tuning—not just AWS’s uptime guarantees. Teams serious about end-to-end performance should also explore cloud performance benchmarking to validate that their configurations meet real-world demands.
Claiming service credits (and why most teams don’t)
Service credits are applied automatically when AWS detects an SLA violation. But you need to verify. Check the AWS Service Health Dashboard for outage history, compare CloudWatch uptime metrics to your SLA threshold, and open a support case if you believe you’re owed a credit.
In practice, most service credits are small—10% of a single month’s charge for one service. If your EC2 bill is $5,000 per month and AWS credits you 10% for one region, that’s $500. Significant, but not transformative.
The bigger value in SLA monitoring is operational: catching underperforming resources, identifying architectural weak points, and preventing repeat failures. Automated platforms like Hykell tie SLA compliance tracking to cost optimization, surfacing which resources are underutilized, which are overprovisioned, and where you can safely reduce spend without compromising reliability.
Tying SLA commitments to cost and risk
AWS SLAs provide a baseline guarantee, but the architecture you build on top determines real-world reliability and cost. Teams that overprovision for theoretical SLAs waste 30–50% on redundancy they don’t need. Teams that underprovision face outages that cost far more than any service credit can recover.
The key is aligning your SLA strategy with your business risk. Mission-critical services (payment processing, customer-facing APIs) should target 99.99% with multi-AZ deployments. Internal tools and dashboards can often run at 99.9% with single-AZ deployments and lower costs. Batch processing and dev/test workloads may need no formal SLA at all, unlocking spot instances and other high-discount options.
For teams juggling these trade-offs, Hykell’s automated cloud cost optimization services automate commitment planning, right-size SLA-driven architectures, and apply the optimal mix of Reserved Instances and Savings Plans—so you get the uptime you need without paying for guarantees you don’t. Book a cost audit to see where your SLA strategy is costing you more than it should.

