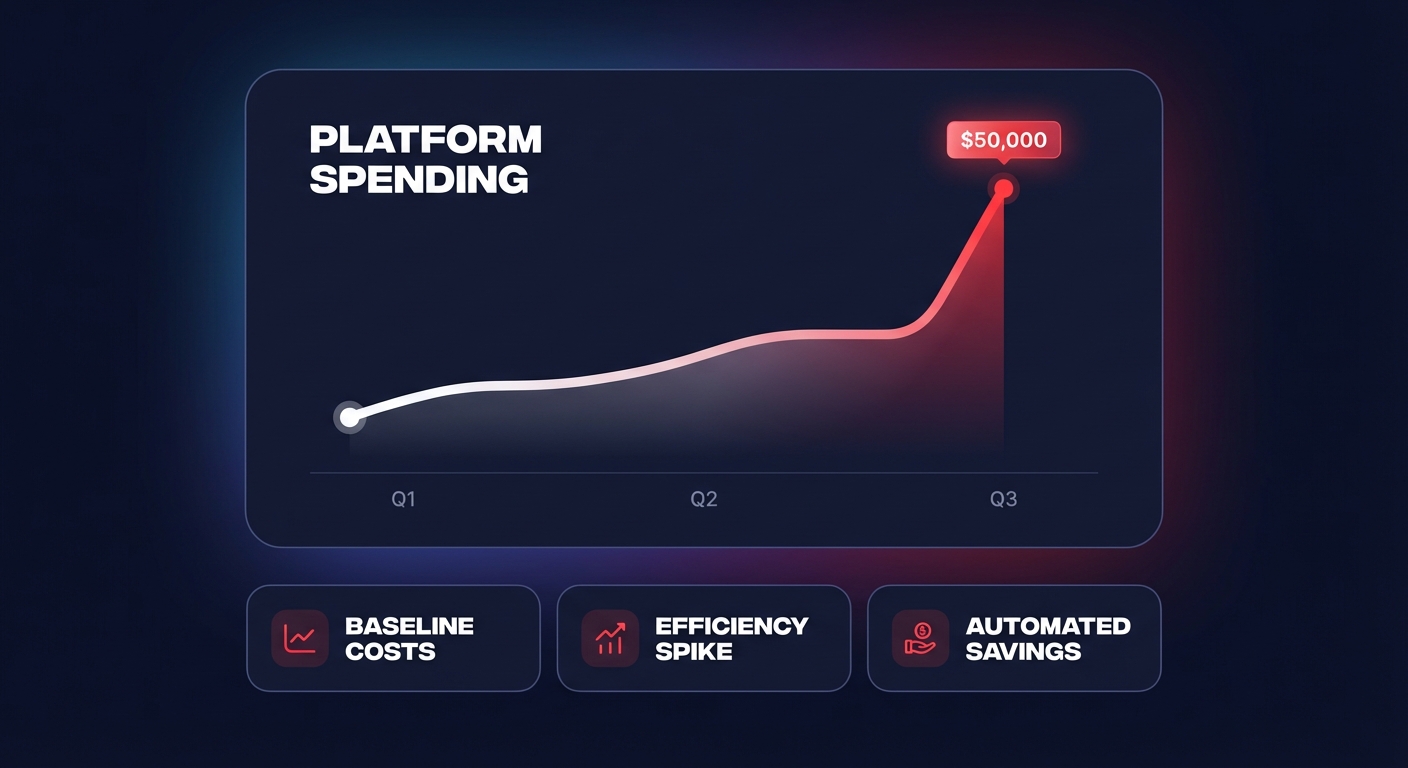
Did a misconfigured Lambda function just burn through your monthly budget in 48 hours? Cloud cost anomalies are the silent killers of ROI, but with automated safeguards and real-time detection, you can catch them before they balloon into five-figure disasters.
What constitutes a cloud cost anomaly?
A cloud cost anomaly is any unexpected variation in spending that deviates significantly from your historical baseline. These are rarely minor fluctuations; instead, they typically stem from technical errors, security breaches, or architectural oversights. Because 30% of total cloud spend represents addressable waste across many organizations, detecting these spikes early is the difference between a minor ticket and an emergency board-level review.
Cloud cost anomalies manifest in several ways, often starting with technical oversights. For example, a serverless function triggered in an infinite loop once cost an e-commerce platform $50,000 in a single event. In another instance, a single misconfigured Lambda function ran unchecked for three months, accumulating $12,000 in unnecessary data transfer fees. Beyond serverless, auto-scaling configuration errors can cause infrastructure costs to spike 10x overnight during a viral product launch. Even idle RDS instances can drain $800 per month undetected if your environment lacks the real-time monitoring baselines necessary to flag underutilized resources.
How to detect anomalies in AWS, Azure, and GCP
Effective detection requires moving beyond fixed budget alerts and adopting machine learning models that understand your “normal” usage patterns. AWS now provides a native, ML-based service that establishes dynamic thresholds based on at least two months of historical data. Since March 2023, this has been automatically enabled for all new Cost Explorer customers. It analyzes combinations of services, accounts, regions, and usage types to flag spikes that a simple budget might miss. A 50% spike in Lambda costs might be invisible in a $100,000 monthly bill, but it is critical if your Lambda spend is typically only $2,000.
In multi-cloud environments, different providers offer varying patterns for detection. Azure cost anomaly detection uses billing history to spot odd charges, with detection typically occurring within 96 hours. This can be enhanced using Cognitive Services for more granular, ML-driven baselines. Similarly, Google Cloud sends notifications when budgets are approached or when usage deviates significantly from historical trends.

Despite these advancements, a primary challenge remains the processing delay. Native billing data often has a 24-hour delay, meaning the anomalies you see today reflect spending from yesterday or earlier. To close this gap, engineering teams often use automated cost dashboards and real-time observability tools to catch surges in resource consumption before the billing API even processes the charges.
A step-by-step investigation workflow
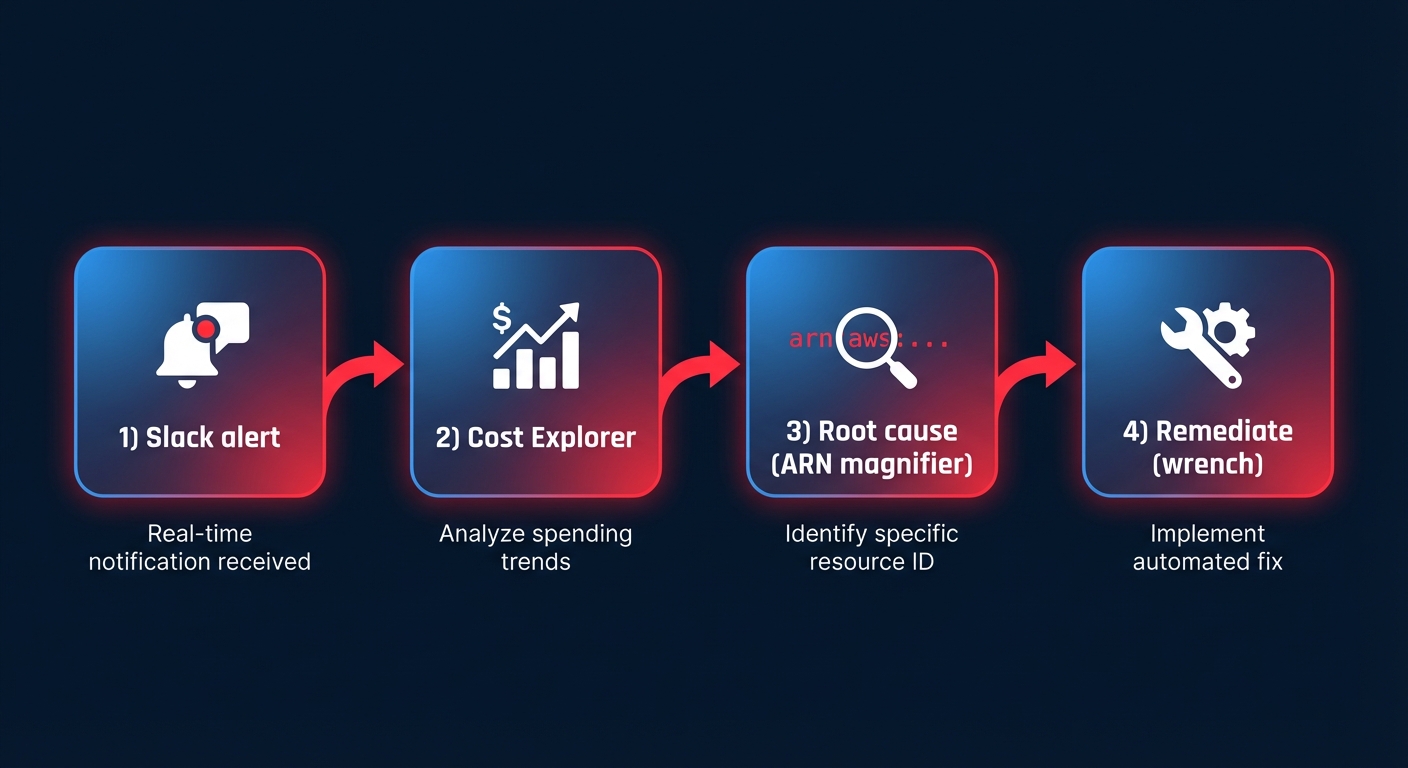
When a cost alert hits your Slack channel, your investigation must be surgical. You can start by assessing the immediate financial impact using AWS Cost Explorer to determine if the spike is a one-time event, such as a large data migration, or a new daily run rate that will persist.
Once the impact is clear, you must identify the specific resource responsible by drilling into the “Usage Type” and “Region.” AWS Cost Anomaly Detection can now identify root causes for anomalies above $1, providing the specific ARN of the resource. After identifying the resource, use AWS CloudTrail to trace the user or process that launched it. This helps you distinguish between an automated CI/CD pipeline deployment and a manual configuration change in the console.
Finally, cross-reference the resource with your established tagging strategy. If a resource is correctly tagged with metadata such as project or environment, you can quickly contact the relevant lead to verify if the surge was intended. This workflow ensures that you move from a vague alert to a remediated root cause in minutes rather than days.
How to prevent recurring cost anomalies
Prevention is built on automated governance rather than manual oversight. You should enforce tagging hygiene using Service Control Policies (SCPs) to deny the creation of any resource that lacks mandatory tags like “Owner” or “CostCenter.” This ensures that when an anomaly occurs, you immediately know who is responsible for the resource.
Regularly conducting a comprehensive cloud cost audit is another essential preventative measure. These audits help you identify over-provisioned resources that act as “slow-motion” anomalies, inflating your baseline spend over time. Furthermore, you can automate non-production shutdowns for development and staging environments to reduce compute costs by up to 70%. This simple automation eliminates the risk of forgotten instances running unchecked over the weekend.
To maintain these guardrails as your infrastructure grows, you can deploy monitors using Terraform for cost anomaly detection. This ensures that every new account or environment is automatically covered by your security and cost guardrails from the moment it is provisioned.
Automating cost management with Hykell
Native tools provide essential visibility, but they rarely fix the underlying problems. DevOps and FinOps teams often find themselves “firefighting” costs manually, which takes hours away from innovation and product development. This is where Hykell transforms your strategy from reactive monitoring to proactive optimization.
Hykell provides an automated cloud cost optimization platform that functions on autopilot. Instead of just alerting you to a spike, Hykell continuously optimizes your AWS rate strategies, rightsizes over-provisioned resources, and eliminates orphaned EBS volumes without requiring any engineering effort. This allows your team to maintain high performance while the platform silently handles the complexities of discount coverage and waste elimination.
By combining real-time cloud observability with automated remediation, Hykell helps companies reduce their AWS bills by up to 40%. Our model is entirely performance-based: we only take a slice of what you save. If we do not uncover hidden savings in your environment, you do not pay.
Stop letting unexpected billing surprises derail your cloud budget. Calculate your potential savings or schedule a deep-dive cost audit with Hykell today to gain full control over your cloud spend.

