Are you paying “hot” storage prices for “cold” data you haven’t touched in months? For many US-based engineering teams, Amazon S3 is a silent budget killer that scales linearly with data growth until it rivals your primary compute spend.
Most organizations treat S3 as a “set it and forget it” service. However, without a systematic approach to tiering and egress management, you are likely overpaying by at least 30%. Reclaiming that budget requires moving beyond basic visibility and implementing a rigorous cloud cost governance framework that balances immediate savings with long-term application reliability.
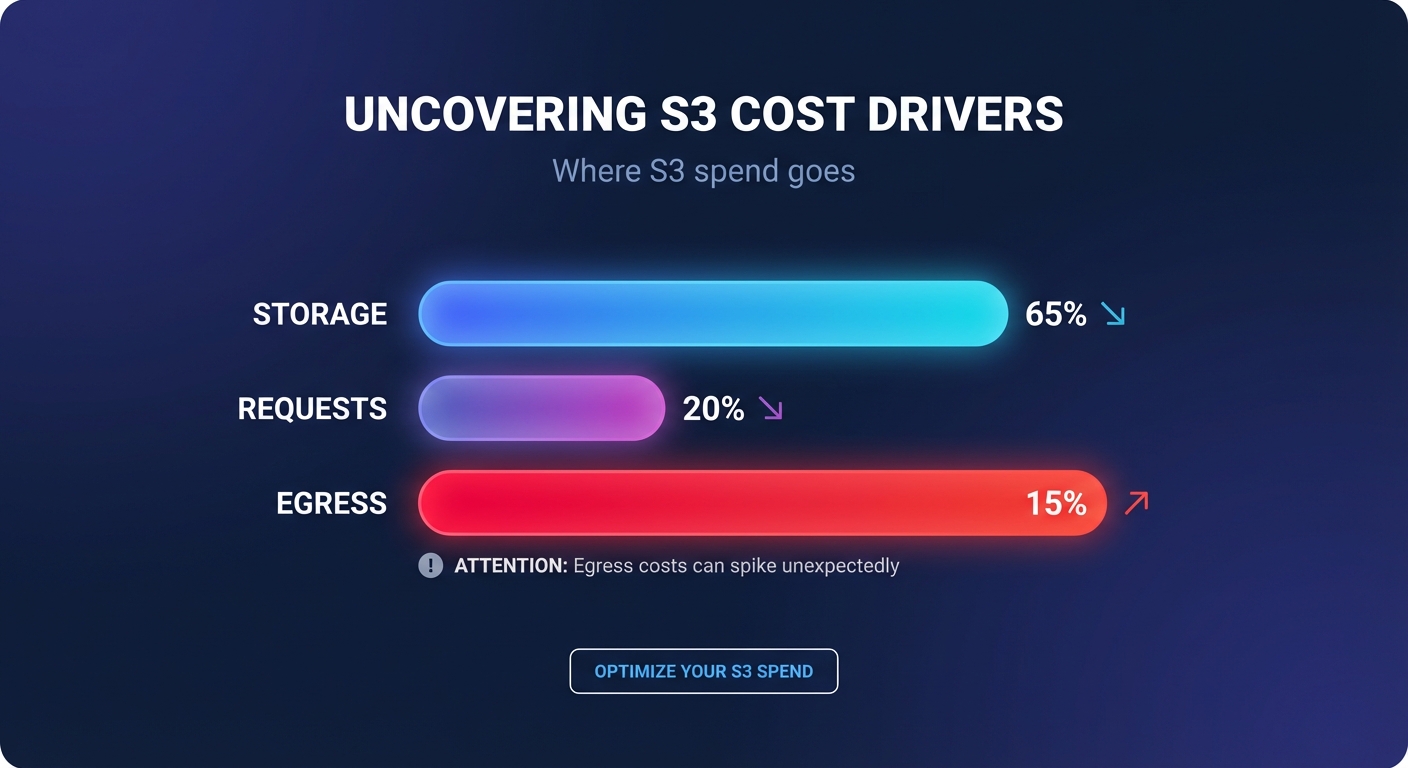
Identify where your S3 spend is actually going
Before you can optimize, you must dissect your monthly bill to find the root causes of overspending. S3 costs are rarely just about the total size of your objects; they are a complex combination of storage volume, request types (such as PUT, GET, and LIST), and often-overlooked AWS egress costs. If you notice your bill climbing faster than your user base, you may be suffering from high API request frequency or redundant data movement.
By leveraging AWS Cost Explorer, you can filter by “Usage Type” to pinpoint whether costs are coming from a specific region or a particular storage class. For more granular insights, S3 Storage Lens provides a centralized dashboard to identify your largest and fastest-growing buckets across your entire organization. This visibility is essential for finding underutilized buckets that are prime candidates for decommissioning or tiering.
Leverage S3 lifecycle policies for automated tiering
The most direct path to cost reduction involves moving data to lower-priced storage classes as it ages. Implementing S3 Lifecycle Policies allows you to automate these transitions based on defined rules, ensuring that data doesn’t sit in the expensive Standard tier longer than necessary. For example, moving data to S3 Standard-Infrequent Access is ideal for objects accessed less than once a month that still require millisecond access times.
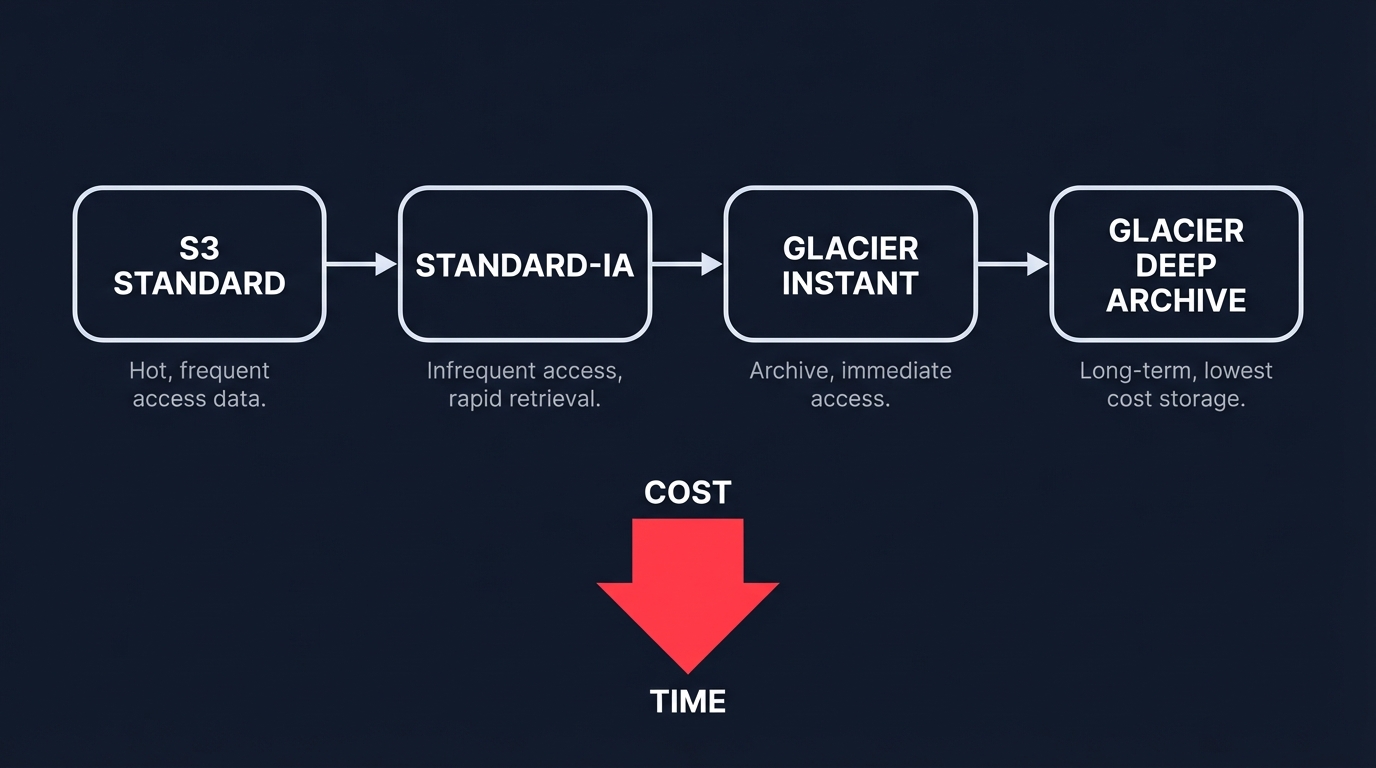
For long-term compliance or archival needs, moving data to S3 Glacier Instant Retrieval or S3 Glacier Deep Archive can yield massive results. Deep Archive offers the lowest-cost storage for data that can tolerate a 12-hour retrieval time. Real-world applications of this strategy are significant; for instance, T-Mobile reduced S3 costs by 40% by managing a massive 1.87 PB data lake through automated policies. Similarly, GE Vernova saves $18,000 per month by archiving objects to Glacier classes, demonstrating that storage tiering is a cornerstone of modern infrastructure management.
Optimize for unpredictable access with Intelligent-Tiering
Manual lifecycle policies work best when access patterns are predictable. However, if your data access is “spiky” or unknown, moving data to an Infrequent Access tier manually can be risky, as sudden bursts of GET requests may trigger high retrieval fees. S3 Intelligent-Tiering solves this by automatically moving objects between access tiers based on actual usage patterns.
This storage class charges a small monthly monitoring fee but eliminates retrieval fees entirely, making it a safe choice for dynamic workloads. Organizations like Bynder achieved 65% storage cost savings on 18 PB of data by using Intelligent-Tiering to manage over 175 million digital assets. This approach allows your team to save money on autopilot without the constant manual intervention of reviewing access logs.
Minimize hidden egress and data transfer fees
Data transfer is frequently the most expensive “hidden” component of an S3 bill. While transferring data into S3 is free, moving it out to the internet or across regions can cost between $0.02 and $0.09 per GB. To mitigate these charges, keep your EC2 instances and S3 buckets in the same region to avoid cross-region transfer fees.
For public-facing assets, integrating Amazon CloudFront can significantly lower egress charges by caching content closer to users, which also improves application performance. Additionally, you can use S3 Select to retrieve only the specific rows you need from large CSV or JSON files rather than pulling the entire object into your application. If your egress costs remain high, auditing cloud storage expenses can help you identify architectural bottlenecks where data is being moved unnecessarily.
Monitor and enforce with automated tooling
High-growth environments move too fast for manual audits to keep up. To maintain continuous control over your storage budget, you must integrate cost metrics into your broader observability strategy. Effective monitoring ensures that one misconfigured script doesn’t result in a surprise five-figure bill at the end of the month.
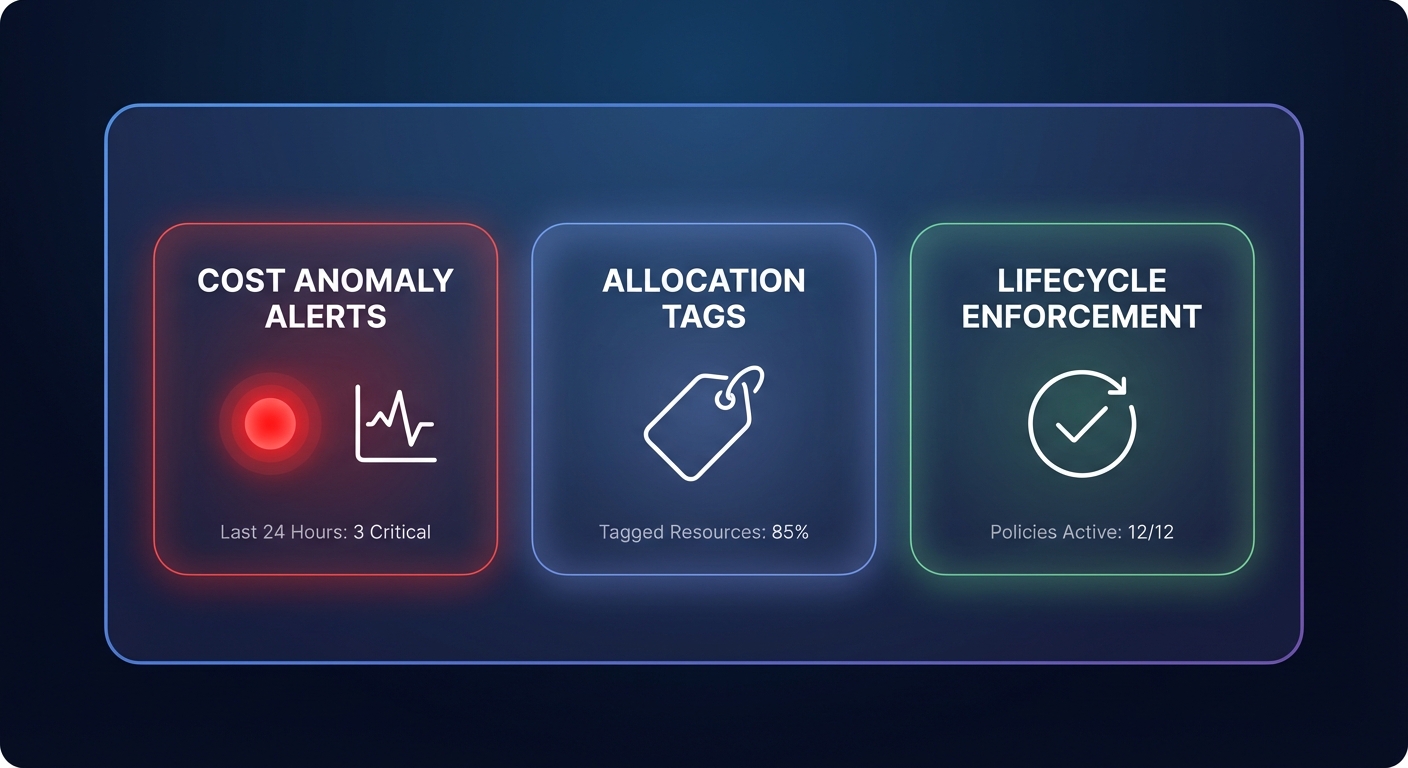
- Implement AWS cost allocation tags to attribute S3 spend to specific products, departments, or development teams, creating financial accountability.
- Enable AWS Cost Anomaly Detection to receive real-time alerts when spending deviates from historical patterns, catching runaway API requests before they escalate.
- Configure lifecycle policies to automatically delete old object versions or incomplete multipart uploads, which can silently bloat your bill over time.
Achieve continuous S3 optimization on autopilot
While AWS provides the native tools to manage costs, the internal engineering effort required to monitor prefixes, adjust lifecycle rules, and right-size storage classes is often too high for busy teams. Hykell removes this burden by providing automated AWS cost optimization that works silently in the background. By identifying underutilized resources and applying precision-engineered rate strategies, Hykell helps companies reduce their total AWS spend by up to 40%.
Hykell’s performance-based pricing model means there is no financial risk to your organization; you only pay a percentage of the savings actually realized. If your S3 costs are spiraling out of control, you can start with a comprehensive cloud audit to quantify your potential savings and put your infrastructure on a path toward sustainable, automated efficiency.