Did you know a one-second delay in page response can slash your conversions by 7%? In the AWS cloud, performance isn’t just a technical metric – it’s a direct driver of your company’s revenue and user retention.
Managing AWS application performance monitoring requires more than just keeping the “lights on.” For engineering leaders and FinOps practitioners, the challenge is maintaining a high-velocity user experience while ensuring that infrastructure costs don’t spiral out of control. When done correctly, a mature performance management practice can reduce service incidents by 30-50% and significantly improve your mean time to resolution (MTTR) by up to 70%.
The shift from monitoring to cloud observability
Traditional monitoring tells you when something is broken; modern cloud observability tells you why. In an AWS environment, this transition is powered by services like CloudWatch Application Signals, which automatically collects metrics and traces to create service maps for distributed applications. This level of visibility allows you to move beyond basic health checks to track Service Level Objectives (SLOs) that actually matter to your business.
By implementing AWS CloudWatch application monitoring, you can correlate performance improvements with financial metrics. For example, instead of just monitoring CPU usage, you might set an SLO ensuring that 99.9% of checkout processes complete in under two seconds. This creates a direct link between technical health and business outcomes, ensuring that every engineering effort supports a specific revenue goal.
Why performance matters for your bottom line
The performance-cost tradeoff is often viewed as a zero-sum game, but that is a misconception. Poorly performing applications often signal inefficient resource usage, which wastes money. By focusing on efficiency, you can unlock significant gains in several key areas:
- User Experience and Revenue: High latency correlates directly with bounce rates. Implementing cloud latency reduction techniques, such as strategic regional deployment or protocol optimization, keeps users engaged and protects your conversion pipeline.
- Scalability and Resilience: An application that isn’t optimized for performance will require more resources to handle the same amount of traffic. Following AWS EC2 auto scaling best practices is essential for handling spikes without overpaying for idle capacity.
- Operational Efficiency: Organizations using advanced observability tools resolve problems significantly faster. This frees up your engineering team to focus on innovation and product development rather than constant firefighting.
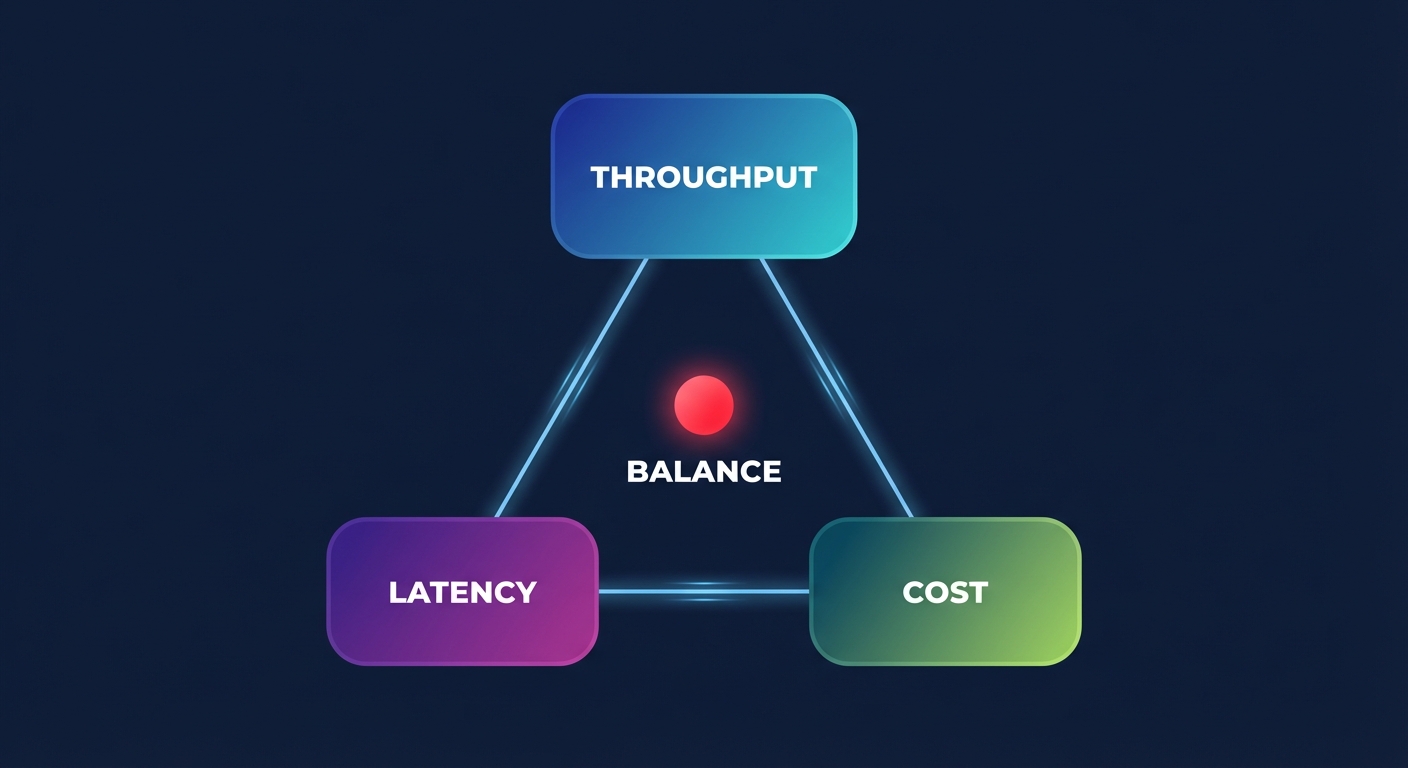
Balancing throughput, latency, and cost
When managing performance on AWS, three technical pillars usually dictate the quality of your user experience: compute, storage, and networking. Optimizing these requires a deep dive into how your resources are provisioned versus how they are actually used.
Compute optimization
Many organizations overprovision their EC2 instances by 30-45%. By right-sizing your instances based on actual usage patterns, you can maintain performance while significantly reducing spend. For workloads that are particularly compute-intensive, you can accelerate your Graviton gains through Arm-based processors, which deliver up to 40% better price-performance over comparable x86 instances.
Storage and I/O
Storage bottlenecks are a frequent cause of application lag, and understanding Amazon EBS latency is critical for database-heavy applications. A common win is migrating from gp2 to gp3 volumes; this move alone can reduce storage costs by 20% while providing more consistent throughput and IOPS.
Network performance
Network latency can be elusive and often expensive if ignored. Using AWS network performance monitoring helps you distinguish between application code issues and underlying infrastructure bottlenecks, such as inter-AZ traffic costs or ISP routing problems.
Integrating performance with FinOps
The most successful AWS-based businesses treat performance and FinOps principles as two sides of the same coin. By correlating performance metrics with cost data, you can identify “zombie” resources or inefficient code that is driving up your bill.
For instance, if your AWS CloudWatch logs pricing is spiking, it might indicate a verbose debugging loop that is both slowing down your app and inflating your observability costs. Mature teams use an “Effective Savings Rate” to measure how well they are utilizing AWS rate optimization strategies, such as Reserved Instances and Savings Plans, without compromising the agility of their infrastructure.
Maintaining peak performance on autopilot
Manually balancing these variables is a full-time job that often pulls senior engineers away from product development. This is where automation becomes a competitive advantage. Hykell helps AWS-based businesses maintain world-class application performance while automatically stripping away cloud waste. Our platform analyzes your actual usage patterns to identify underutilized resources and execute AWS EC2 performance tuning recommendations without requiring code changes.
We specialize in deep architectural optimizations – like transitioning to Graviton or optimizing EBS throughput – that typically reduce total AWS spend by up to 40%. Because Hykell operates on a pay-from-savings model, you only pay a fraction of what we save you. We ensure your infrastructure is perfectly right-sized for your current load, giving you the reliability and scalability you need to grow without the financial overhead of overprovisioning.
To see how much your business could be saving while improving your application’s speed, use our cost savings calculator or book a comprehensive cost audit today.