Are you paying for speed or just over-provisioning to hide bottlenecks? Most AWS environments run at a meager 30–40% utilization, meaning you are likely paying a massive “complexity tax” that scales with your traffic every single month.
Right-sizing compute with the Graviton advantage
The gap between provisioned capacity and actual demand is where most cloud budgets disappear. Engineering teams often maintain 30–50% safety buffers to avoid performance degradation during spikes, but this manual padding is an expensive way to manage scale. To tune compute performance without sacrificing stability, you must move beyond generic instance families. Achieving effective automated AWS rightsizing starts with matching your workload’s specific resource profile – whether it is CPU-bound, memory-intensive, or I/O-heavy – to the correct instance generation.
Practical AWS EC2 performance tuning often involves upgrading to the latest hardware generations to capture better price-performance. For instance, moving from m6i to m7g instances can yield approximately 15% per-instance savings while simultaneously improving throughput. The most significant lever available to modern DevOps teams is the migration to ARM-based processors. You can accelerate your Graviton gains to achieve up to 40% better price-performance over comparable x86 instances. Because Graviton is purpose-built for cloud-native workloads like microservices and data processing, it offers higher compute density and lower latency at a significantly lower unit cost.
Eliminating storage bottlenecks in Amazon EBS
Storage latency is the silent killer of application responsiveness, often manifesting as sluggishness even when CPU usage remains low. In the AWS ecosystem, Amazon EBS latency is measured as the time between an I/O request and its completion. Maintaining predictable storage performance requires a proactive shift from legacy volume types to modern alternatives. Transitioning from gp2 to gp3 is a critical move, as it allows you to decouple IOPS and throughput from volume size. This migration alone cuts storage costs by 20% while ensuring consistent latency by avoiding the performance cliffs associated with burst-credit depletion.
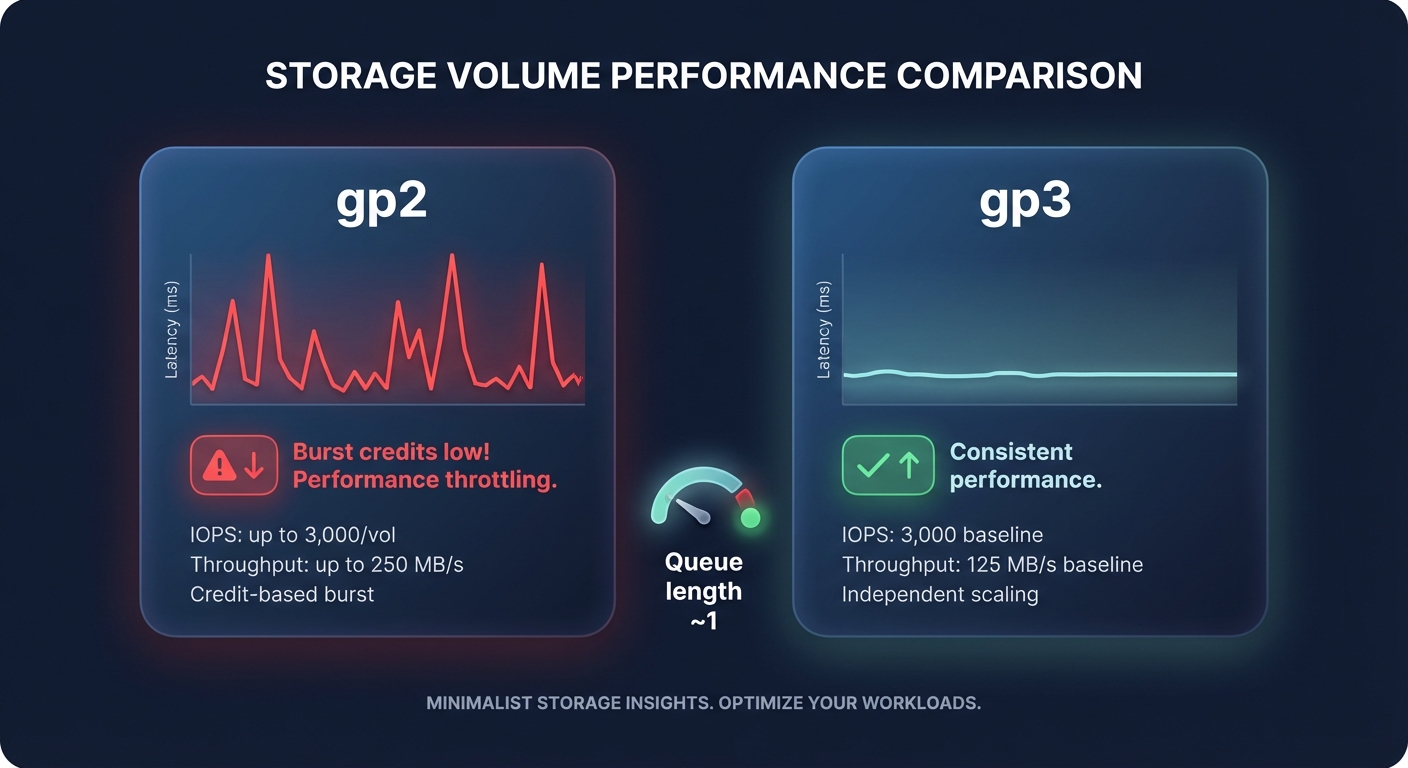
Beyond volume type selection, you must monitor VolumeQueueLength to ensure your storage is not overwhelmed. For databases and latency-sensitive applications, you want your queue length to hover near one; a rising queue combined with high VolumeThroughputPercentage indicates that your volume is maxed out and requests are being throttled. It is also vital to verify that your EC2 instance possesses the EBS-optimized bandwidth required to handle your provisioned throughput. A high-performance storage strategy is effectively neutralized if the instance type acts as a bottleneck, preventing data from moving efficiently through the pipe.
Database efficiency: tuning Aurora and RDS
Relational databases are frequently the most expensive and performance-sensitive components of your infrastructure. Tuning AWS Aurora performance requires a disciplined focus on memory management and I/O reduction. A primary metric to watch is the BufferCacheHitRatio, which should ideally remain above 90%. If this ratio drops, your database is forced to read from disk, which is orders of magnitude slower than reading from memory. In these scenarios, upgrading to a memory-optimized instance family like R7g is far more effective than simply increasing provisioned storage IOPS.
For read-heavy environments, AWS RDS MySQL performance tuning best practices suggest offloading traffic to read replicas to prevent the primary instance from becoming a bottleneck. This horizontal scaling ensures that product catalog searches or reporting queries do not impact write availability. Additionally, enabling Aurora Auto Scaling allows your cluster to add or remove replicas dynamically based on actual demand, allowing you to balance strict performance requirements with a lean budget.
Reducing network latency across global infrastructure
Network performance is determined by how efficiently data moves between your services and your end users. You can significantly reduce cloud latency by optimizing your internal and external connectivity patterns. For tightly coupled microservices, using cluster placement groups ensures that instances are physically close within an Availability Zone, which minimizes inter-node latency. You should also verify that the Elastic Network Adapter (ENA) is enabled on your instances to provide the high bandwidth and low latency required for modern distributed systems.
In hybrid cloud environments, the public internet is often too unpredictable for mission-critical traffic. Implementing AWS network performance monitoring can reveal where public routing is failing your users. In these cases, private connectivity via AWS Direct Connect can reduce network latency by up to 60% compared to standard routing. This stabilization is essential for financial services or real-time gaming applications where even minor jitter can lead to a degraded user experience.
Building a high-fidelity observability stack
You cannot optimize what you do not measure, but observability itself can quickly become a massive cost center. Comprehensive AWS CloudWatch application monitoring should prioritize the “Four Golden Signals”: latency, traffic, errors, and saturation. However, without careful management, the Amazon CloudWatch Logs pricing model can consume up to 30% of your total monthly bill. For example, a mid-sized SaaS with 5 TB of monthly ingestion and 20 TB of storage can easily face bills exceeding $3,100 just for logging.

To maintain visibility without the “observability tax,” you should set aggressive retention policies and use metric filters to capture only the essential data needed for troubleshooting. High-fidelity monitoring should also include distributed tracing through AWS X-Ray, which allows you to pinpoint exactly which microservice or database query is adding milliseconds to your tail latency. By distinguishing between application-level bugs and underlying infrastructure bottlenecks, your team can resolve issues faster and avoid unnecessary over-provisioning.
Put your AWS performance on autopilot with Hykell
Manual performance tuning is a continuous, data-heavy struggle that often leaves engineering teams reacting to spikes rather than proactively optimizing for efficiency. This is where Hykell transforms your infrastructure management by putting best practices on autopilot. We dive deep into your environment to identify over-provisioned instances, underutilized EBS volumes, and ideal candidates for Graviton migration.
By combining real-time observability with precision AWS rate optimization, Hykell ensures you receive the highest possible performance for every dollar spent. Our platform identifies the “action gap” where native tools stop; we do not just provide a list of suggestions – we implement changes that can reduce your total AWS costs by up to 40% without requiring ongoing manual engineering effort.
Ready to see how much you could reclaim while improving your application’s responsiveness? You can calculate your potential savings with Hykell or book a comprehensive performance audit today. Our model is entirely risk-free: we only take a slice of what you save. If you don’t save, you don’t pay.