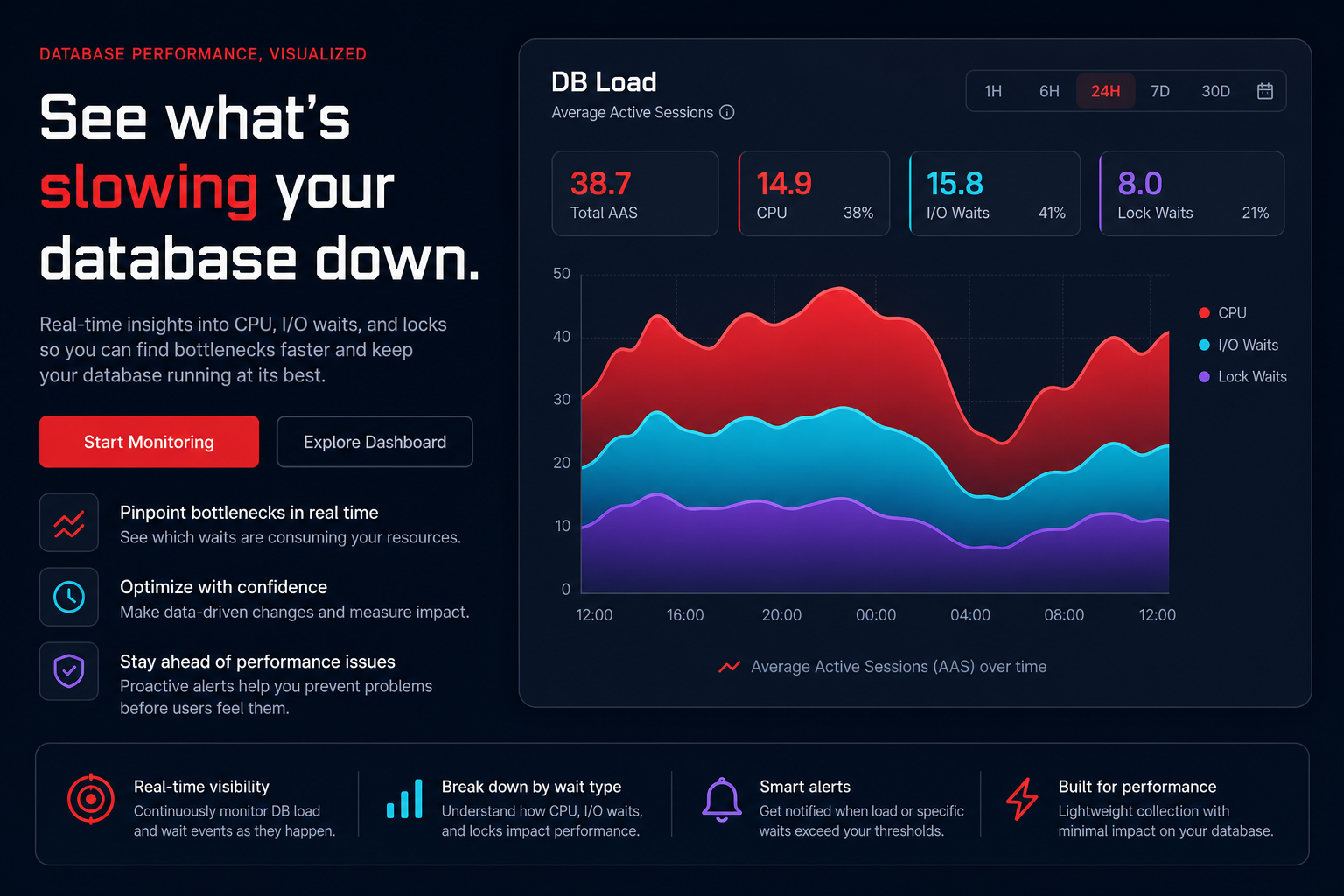
Can you accurately measure the dollar value of a single millisecond? For engineering leaders, the gap between “good enough” performance and optimized infrastructure represents hundreds of thousands of dollars in wasted annual spend.
The reality of cross-provider performance benchmarks
Comparing AWS, Azure, and Google Cloud Platform (GCP) requires looking past marketing SLAs that promise 99.9% to 99.99% availability. While an AWS vs Azure performance comparison reveals that AWS provides the most consistent performance across global regions, GCP often leads in raw network speed via its private fiber backbone, and Azure frequently shows lower disk latency for specific I/O-heavy workloads.
For US-based businesses deeply integrated into the Amazon ecosystem, the real performance gains are rarely found in switching providers, but rather in granular AWS EC2 performance tuning. Benchmarking should not just measure raw CPU cycles; it must account for the Effective Savings Rate (ESR). Top-performing teams maintain an ESR above 25%, effectively turning their performance metrics into a direct lever for capital efficiency. When these benchmarks are ignored, organizations often fall into the trap of over-provisioning, which results in average CPU utilization hovering between a wasteful 10% and 20%.
Decoupling throughput from cost at the instance level
A common pitfall for FinOps teams is over-provisioning storage to solve for latency spikes. When you move from legacy gp2 volumes to gp3, you can decouple IOPS from volume size, reducing costs by 20% while maintaining the throughput your application actually requires. Similarly, migrating to AWS Graviton instances offers up to 40% better price-performance over x86 alternatives, provided your binaries are ARM-compatible.
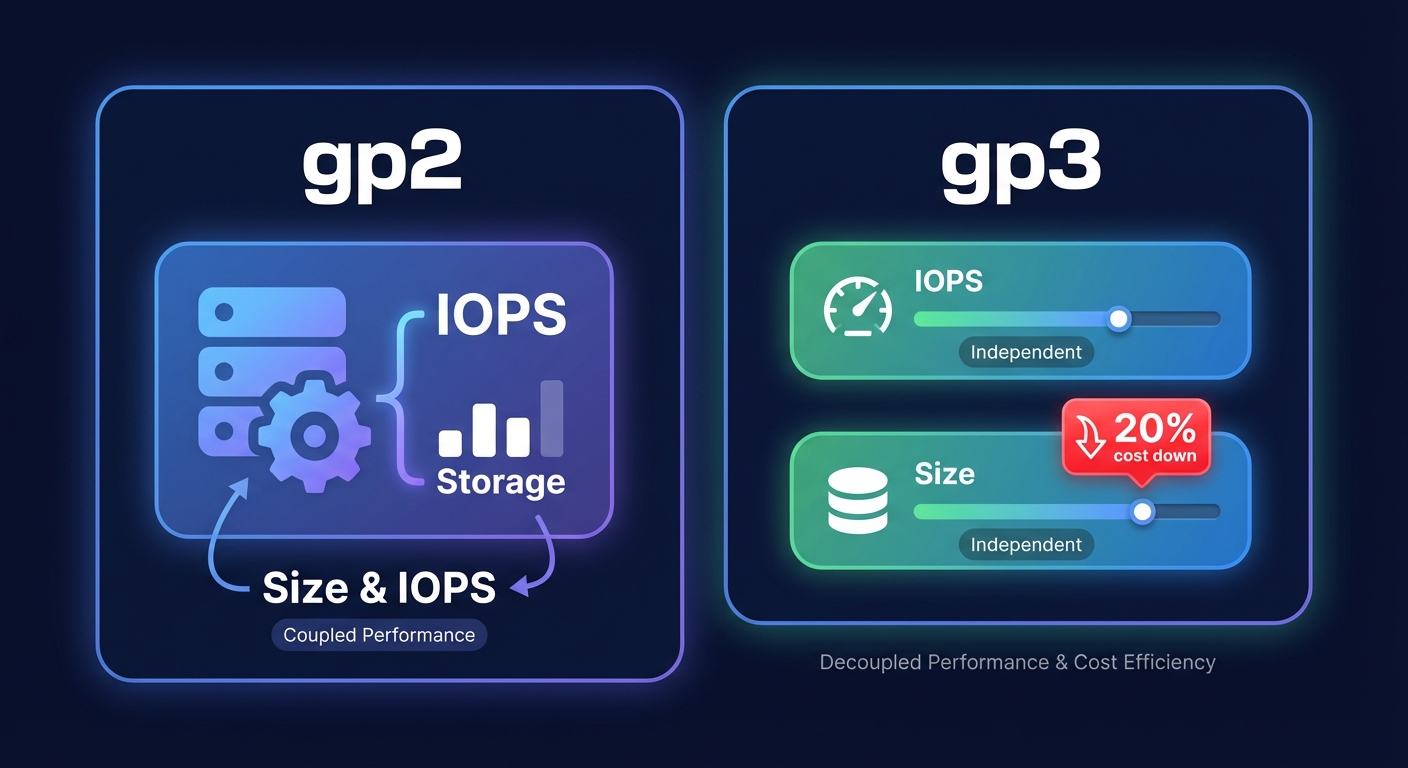
Instance selection must be a data-driven process rather than a guessing game. Moving a workload from an M7i to a C7i might reduce costs by 15-20% if your memory utilization is consistently low, but without real-time observability, these shifts often introduce unexpected bottlenecks. You must continuously monitor VolumeThroughputPercentage and BurstBalance to ensure your infrastructure does not hit performance cliffs that impact the end-user experience. Smaller instances can also provide finer-grained scaling and spread risk, allowing you to match resources to workload demands dynamically.
Why manual performance optimization fails at scale
Most engineering teams treat performance and cost as a one-time architecture project. In reality, AWS releases new instance generations every 18 to 24 months, and regional pricing can vary by as much as 15%. Keeping up with these changes manually creates a massive “engineering tax” that distracts your best developers from shipping products. This tax is exacerbated by the complexity of managing orphaned snapshots and over-provisioned IOPS, which often account for nearly 30% of total EBS spending.
Hykell solves this by acting as an automated extension of your DevOps and FinOps teams. Our platform performs detailed cost audits and identifies underutilized resources across EC2, EBS, and Kubernetes. Instead of your team spending weeks on benchmarking and migrations, the Hykell automated savings engine applies rate optimizations and right-sizing on autopilot. This ensures your stack always leverages the latest hardware generations – like moving from m6i to m7g for immediate 15% savings – without requiring manual intervention.
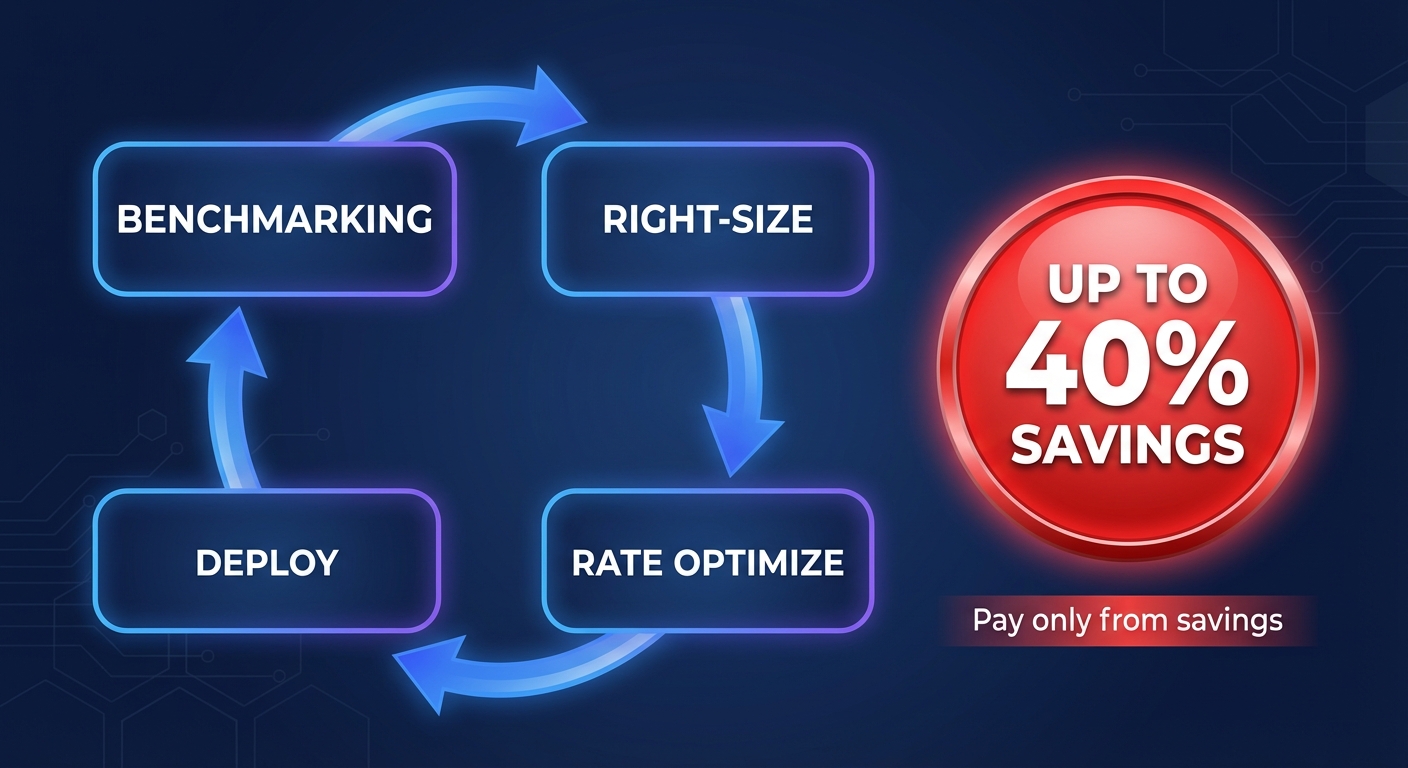
Achieving 40% savings on a success-based model
The challenge with traditional FinOps tools is the commitment risk. Committing to a three-year Savings Plan can yield 72% discounts, but it often locks you into specific architectures that may become obsolete. Hykell leverages AI-powered AWS rate optimization to blend Reserved Instances and Savings Plans dynamically. This approach maximizes your ESR – often reaching 30-40% or more – without the risk of over-commitment or the need for manual forecasting.
To ensure total transparency, we operate on a simple, risk-free pricing model: we only take a slice of the actual savings we generate. If you do not save, you do not pay. This aligns our incentives with your performance needs, ensuring your infrastructure is as lean as it is powerful.
Stop letting performance overhead eat your margins. Calculate your potential savings with Hykell and see how our automated intelligence can reduce your AWS spend by up to 40% without sacrificing a single millisecond of performance.